Автоматизация процесса тестирования при помощи методологии и инструментальных средств IBM Rational. Часть II
Инструментальные средства поддержки процесса тестирования
Новичков Александр, Костиков Александрwww.cmcons.com
info@cmcons.com
Часть первая - Введение в процесс тестирования
Часть вторая — Инструментальные средства поддержки процесса тестирования
Введение
Средства тестирования для разработчиков
Организация тестирования
Quantify, Purify и PureCoverage
Профилировщик Quantify
Введение
Запуск приложений
Анализ информации
«Run Summary»
Дерево вызовов «Call Graph»
Список вызовов функций «Function List»
Сравнивание запусков «Compare Runs»
API
Сохранение данных и экспорт
Purify. Контроль над утечками памяти
Введение
Основные параметры вывода
Сообщения об ошибках и предупреждениях
Работа с фильтром
API
Сохранение данных и экспорт
Параметры тестирования
PureCoverage. Проверка области охвата кода
Введение
Особенности запуска
Работа с PureCoverage
Анализ результатов тестирования
API
Сохранение данных и экспорт
Итог
Дополнительные возможности средств тестирования для разработчиков
Способы запуска
Тестирование сервисов Windows NT/2000/XP
Основные свойства средств Purify, Quantify и PureCoverage
Инструментальные средства поддержки процесса тестирования
Введение
к оглавлениюПриведем список программных продуктов, рекомендованных к использованию в тестировании на разных этапах.
Вот их наименования и краткое описание:
Rational Quantify. Профилирование производительности;
Rational Purify. Отслеживание ошибок с распределением памяти;
Rational PureCoverage. Отслеживание области покрытия кода;
Rational TestManager. Планирование тестирования;
Rational Robot. Выполнение функциональных тестов.
Программные продукты будут описаны в порядке применения в проектах. Сначала рассмотрим средства тестирования для разработчиков (Quantify, Purify, PureCoverage). Данные средства неразрывно связаны с языком реализации и со средой разработки. Примеры, приведенные в книги ориентированы на язык программирования С++ и частично на С#. В связи с тем, что на момент написания была доступна только бета-версия Visual Stu-dio .NET, то мы в основном ориентировались на версию 6.0, лишь изредка демонстрируя возможности новой среды. Тоже касается и языка реализации C#. Примеры его использования также будут встречаться, но все же основное внимание будет уделено языку реализации С++, имеющем наивысший рейтинг среди языков для реализации крупных программных систем. К сожалению, за бортом остались Java и Basic, но мы надеемся, что разработчики воспримут все написанное здесь как модель реализации, подходы которой совместимы со многими языками программирования.
В следующей части перейдем к функциональному и нагрузочному тестированию. Начнем рассмотрение функционального тестирования с его планирования, чьи данные неразрывно связаны с требованиями, полученными на этапе определения требований к системе. Test Manager, в этом разрезе является как средством планирования тестирования, так средством реализации различных видов тестирования, так и средством предоставления финальной, пост — тестовой, отчетности. Далее воспользуемся продуктом Robot, который осуществляет физическую запись скриптов тестирования, с их последующим воспроизведением.
Ознакомимся с визуальными и ручными режимами составления тестов посредством Robot. Научимся составлять как функциональные скрипты так и варианты нагрузочных скриптов. Рассмотрим различные режимы работы продукта. Для полного понимания возможностей, опишем основные синтаксические нотации скриптовых языков SQA Basic.
В завершении опишем связи средств тестирования с остальными программными продуктами Rational.
Средства тестирования для разработчиков
к оглавлениюОрганизация тестирования
к оглавлениюКак при приемочном тестировании, так и при регрессионном разработчик должен предоставить не только работающий код, удовлетворяющий начальным требованиям, но и делающий это максимально безукоризненно с точки зрения производительности и устойчивости. В дополнение, разработчик должен максимально тщательно проверить исполнение всех строчек написанного им кода, во избежание дальнейших несуразностей, ведь одна из часто встречаемых ошибок — это копирование блоков программного кода в разные части программы, при том, что не все ветви первоначального блока были обработаны и протестированы.
Подобные первоначальные ошибки сводят на «нет» дальнейшее функциональное тестирование, так как низкокачественный код не позволяет тестерам быстро писать скрипт, реализующий тестирование новой формы, так как она полна странностей. Доработка, доработка, доработка...
Интересная деталь: процессоры работают быстро, шины работают быстро, память тоже быстро, а вот программное обеспечение из года в год, от версии к версии работает все медленнее и медленнее, потребляя при этом на порядок больше ресурсов, нежели чем предыдущие версии. Не спасают положение даже оптимизирующие компиляторы! Вторая не менее интересная деталь заключается в скорости разработки. Вы не обращали внимания на то, что аппаратные продукты (процессоры и прочее) обновляются гораздо чаще и выпускаются с меньшим числом ошибок?
Проблема кроется здесь в разных подходах к реализации программного кода в хардверных и софтверных компаниях. В софтверных компаниях, обычно, нет строго организованного процесса тестирования, нет строгой регламентации процесса кодирования, а сам процесс кодирования является особым видом искусства. То есть налицо пренебрежение основополагающими принципами промышленного производства, регламентирующими роли и процессы, входные и выходные значения.
Из нашего опыта работы с партнерами мы знаем не понаслышке о жестких, и даже, жестоких требованиях к программному обеспечению, прошиваемому в аппаратуру, скажем так, у одной компании производителя сотовых телефонов есть требование, в соответствии с которым сотовому телефону «разрешается» зависнуть один раз в год при непрерывной эксплуатации. И это, не говоря о том, что все пункты меню соответствуют начальным требованиям на 100%.
Вот и получается, что при вопросе: «Согласны ли вы, чтобы ваш телефон работал на основе обычной операционной системы (Windows, Unix... или им подобными)?», Традиционно следует — «нет»!
Поскольку этап тестирования кода приложения можно отнести к тестированию «прозрачного ящика», когда важен код приложения, то мы попробуем описать основные рекомендации по тестированию для данного этапа, которые почерпаны из личного опыта и основаны на здравом смысле и принципах разумной достаточности. То есть, мы сначала рассмотрим общие требования к качеству кода, а потом проведем ассоциацию с инструментами Rational, которые позволят решить проблемы данного участка.
Следующие недостатки (относительные) программного кода могут потенциально привести приложение к состоянию зависания (входа в вечный цикл) или к состоянию нестабильности, проявляемой время от времени (в зависимости от внешних факторов):
- Использование рекурсии. Всем известна практическая ценность рекурсии для большого числа задач, особенно математических, но рекурсия является и источником проблем, поскольку не все компиляторы и не во всех случаях способны правильно отрабатывать рекурсию. Посему очень часто в требованиях на разработку вводится требование на отсутствие рекурсивных функций. Quantify ведет статистический анализ по вызовам функций и она выдает имена всех рекурсивных функций.
- Степень вложенности процедур (функций). В программе можно создать любое число функций (классов), вложить их друг в друга, а потом удивляться почему та или иная функция работает с не той производительностью. Если в требованиях на разработку ограничить полет фантазии разработчиков, то получится более быстрое приложение. Статистику по вложенности и скорости даст Quantify.
- Соглашения о именах. Также оговаривается в требованиях на разработку. Необходимо ввести единый стиль наименования функций, во избежание появления дублей и непонятных имен, что тормозит развитие проекта. Quantify также реализует поиски рассогласовании в именах.
- Использование указателей. Язык С и С++ трудно представить без указателей, даже невозможно. Но, являясь гибким и мощным механизмом обращения к памяти, они же являются минами замедленного действия, проявляющими себя в самые неподходящие моменты. Если проект не может существовать без указателей, то все ошибки, связанные с их неправильной работой позволит отловить Purify.
- Не целевое использование переменных и идентификаторов. Сюда попадают и ошибки связанные с операциями чтения и записи файлов до их открытия или после закрытия. Это и присвоение в переменных до их инициализации. Это и наличие лишних переменных. Эти неточности также могут привести к нестабильности приложения. Purify обрабатывает данную категорию ошибок.
- Не целевое использование блоков данных. Под эту категорию попадают ошибки связанные с распределением памяти, например, невозвращение блоков памяти после их использования. С точки зрения функциональности подобная ошибка не совсем ошибка, так как целостность приложения не нарушается и к сбоям не ведет. Побочный эффект — это замусоривание системы ненужными данными и быстрое «истекание» системных ресурсов. Данный вид отлавливается Purify.
- Присутствие участков кода не исполнявшихся в течении определенного времени. Также потенциальная ошибка, так как не выполненный код может содержать ошибки. PureCoverage отлавливает данный вид ошибок.
Quantify, Purify и PureCoverage
к оглавлениюДля осуществления всех функций по тестированию программных модулей, все три продукта используют специальную технологию Object Code Insertion, при которой бинарный файл, находящийся под тестированием, насыщается отладочной бинарной информацией, обеспечивающей сбор информации о ходе тестирования.
Отметим общие черты для всех трех программных продуктов. Для сбора и обработки информации программам тестирования нужны два файла: исполняемый модуль и его исходный текст. Исполняемый модуль насыщается отладочным кодом, а наличие исходного текста позволяет разработчику легко переключаться между схематическим отображением и кодом тестируемого приложения.
На код накладываются дополнительные особые ограничения, а именно: тестируемый код должен быть получен при помощи компиляции с опцией «Debug», то есть должен содержать отладочную информацию. В противном случае Quantify, Purify и PureCoverage не смогут правильно отображать (вообще не смогут отображать) имена функций внутренних модулей тестируемого приложения. Исключения могут составлять только вызовы внешних модулей из dll-библиотек, поскольку метод компоновки динамических библиотек позволяет узнавать имена функций.
Отсюда можно сделать простой вывод: тестировать приложения можно даже не имея отладочной информации в модуле и при отсутствии исходных текстов, но в этом случае разработчик получает статистику исключительно по внешним вызовам.
Все три продукта способны проводить особые виды тестирования, такие как тестирование сервисов NT\2000\XP.
Программные продукты могут работать в трех режимах:
- Независимом графическом. В этом случае каждое средство запускается индивидуально а тестирование осуществляется из него в графическом режиме;
- Независимом командном. Данный режим характеризуется управлением ходом насыщения тестируемого модуля отладочной информации из командной строки;
- Интегрированном. Этот режим позволяет разработчикам не выходя из привычной среды разработки (Visual Studio 6.0 или .NET) прозрачно вызывать инструменты Quantify, Purify и PureCoverage.
Из дополнительных возможностей всех инструментов хочется отметить наличие специального набора файлов автоматизации, разрешающих разработчикам еще на этапе разработки внедрять С-образные вызовы функций сбора информации по тестированию в свои приложения, получая при этом максимальный контроль над ними.
Средства анализа, строенные в Quantify, Purify и PureCoverage позволяют удовлетворить детально контролировать все нюансы в исполнении тестируемого приложения. Здесь и сравнение запусков, и создание слепков в ходе тестирования и экспорт в Excel для построения точных графиков множественных запусков.
Особо хочется отметить языковую «всеядность» продуктов.
Поддерживаются следующие языки программирования:
- Visual C\C++\C# в exe-модулях, dll-библиотеках, ActiveX-компонентах и COM-объектах;
- Поддерживаются проекты на Visual Basic и Java Applets (с любой виртуальной машиной);
- Дополнительно можно тестировать дополнительные модули к MS Word и Ms Excel.
Профилировщик Quantify
к оглавлениюВведение
к оглавлениюQuantify, вставляя отладочный код в бинарный текст тестируемого модуля, замеряет временные интервалы, которые прошли между предыдущим и текущими запусками. Полученная информация отображается в нескольких видах: табличном, графическом, комбинированном.
Статистическая информация от Quantify позволит узнать какие dll библиотеки участвовали в работе приложения, узнать список всех вызванных функций с их именами, формальными параметрами вызова и с статистическим анализатором, показывающим сколько каждая функция исполнялась.
Гибкая система фильтров Quantify позволяет, не загромождая экран лишними выводами (например, системными вызовами), получать необходимую информацию либо только о внутренних, программных вызовах либо только о внешних, либо комбинируя оба подхода.
Вооружившись полученной статистикой, разработчик без труда выявит узкие места в производительности тестируемого приложения и устранит их в кратчайшие сроки.
Запуск приложений
к оглавлению
Рисунок 1 показывает действия после выбора «File->Run», в результате которого можно выбрать имя внешнего модуля и аргументы его вызова.
В качестве параметров настройки можно выбрать метод вставки отладочного кода:
- Line. Наилучший способ вставки отладочного кода. Замеряется время исполнения каждой строки тестируемого приложения.
- Function. То же самое, что и для «line», но с замером для времени исполнения вызываемых функций.
- Time. Осуществляет сбор временной информации и преобразует ее в машинные циклы.
По умолчанию Quantify собирает статистическую информацию в модуле тестируемого продукта и во всех внешних библиотеках.
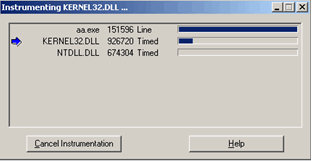
Начало насыщения тестируемого приложения сопровождается появлением окна инструментирования, в котором построчно отображаются все модули, вызываемые основным. Данные модули, как говорилось выше, насыщаются отладочным кодом и помещаются в специальную директорию «cache» по адресу «\rational\quantify\cache». Отметим, что первоначальный запуск инструментирвания процесс длительный, но каждый последующий вызов сокращает общее время ожидания в силу того, что вся необходимая информация уже есть в Кеше.
С точки зрения дисковой емкости, файл (кэшируемый) с отладочной информацией от Quantify вдвое длиннее своего собрата без отладочной информации.
Анализ информации
«Run Summary»
к оглавлениюПлавно переходим к следующей стадии тестирования, собственно, к сбору информации. По окончании процесса насыщения отладочным кодом модулей тестируемого приложения, Quantify переходит к его исполнению, производимым, обычным образом, за одним исключением: запись состояний тестируемого приложения продолжает проводиться в фоновом режиме.
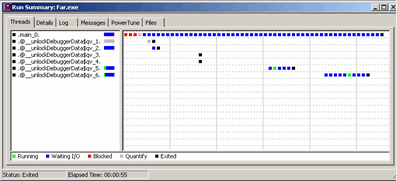
Рисунок 3 демонстрирует фрагмент окна «Summary», в котором производится запись состояния тестируемого приложения. Причем, что очень примечательно, тестирование производится не только для простого приложения, но и для много поточного. В последнем случае (см. рисунок 3), тестируется каждый поток отдельно. В любом случае, даже если приложение однопоточное, то имя основного (единственного) потока именуется как «.main_0», что представляется вполне логичным.
Информационный график постепенно наполняется квадратами разного цвета, демонстрирующими текущее состояние тестируемого приложения.
Отметим некоторые из них:
- Running. Начало исполнения потока;
- Waiting I\O. Ожидание действий по вводу\выводу;
- Blocked. Блокирование исполнения потока;
- Quantify. Ожидание вызова модуля Quantify;
- Exited. Окончание исполнения потока.
Важный аспект при тестировании — получение статистической информации о количестве внешних библиотек, которые вызывало основное приложение, а также элементарное описание машины, на которой проводилось тестирование. Последнее особенно важно, так как бывает, что ошибка проявляется только на процессорах строго определенной серии или производителя. Все статистические аспекты решаются внутри окна «Summary».
Следующие два примера показывают статистическую информацию:
(1) Общий отчет — «Details»:
Program Name: C:\projects\aa\Debug\aa.exe
Program Arguments:
Working Directory: C:\projects\aa\Debug
User Name: Alex
Product Version: 2002.05.00 4113
Host Name: ALEX-GOLDER
Machine Type: Intel Pentium Pro Model 8 Stepping 10
# Processors: 1
Clock Rate: 847 MHz
O/S Version: Windows NT 5.1.2600
Physical Memory: 382 MBytes
PID: 0xfbc
Start Time: 24.04.2002 14:17:38
Stop Time: 24.04.2002 14:17:52
Elapsed Time: 13330 ms
# Measured Cycles: 191748 (0 ms)
# Timed Cycles: 2489329 (2 ms)
Dataset Size (bytes): 0x4a0001.
(2) «Log»
Quantify for Windows,
Copyright (C) 1993-2001 Rational Software Corporation All rights reserved.
Version 2002.05.00; Build: 4113;
WinNT 5.1 2600 Uniprocessor Free
Instrumenting:
Far.exe 620032 bytes
ADVAPI32.DLL 549888 bytes
ADVAPI32.DLL 549888 bytes
USER32.DLL 561152 bytes
USER32.DLL 561152 bytes
SHELL32.DLL 8322560 bytes
SHELL32.DLL 8322560 bytes
WINSPOOL.DRV 131584 bytes
WINSPOOL.DRV 131584 bytes
MPR.DLL 55808 bytes
MPR.DLL 55808 bytes
RPCRT4.DLL 463872 bytes
RPCRT4.DLL 463872 bytes
GDI32.DLL 250880 bytes
GDI32.DLL 250880 bytes
MSVCRT.DLL 322560 bytes
MSVCRT.DLL 322560 bytes
SHLWAPI.DLL 397824 bytes
SHLWAPI.DLL 397824 bytes
Для разработчика или тестера информация (информационный отчет), представленная выше, способна пролить свет на те статистические данные, которые сопровождали, а точнее, формировали среду тестирования.
Дерево вызовов «Call Graph»
к оглавлениюСледующий интереснейший способ анализа конструкции приложения — это просмотр дерева вызовов. Окно, показанное на 4 рисунке, показывает только фрагмент окна с диаграммой вызовов.
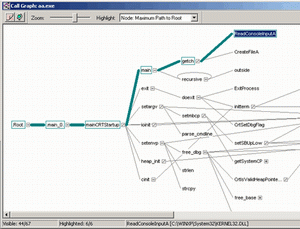
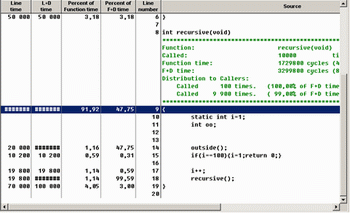
Обратите внимание на количество и последовательность вызова различных модулей потока «main». Жирная линия показывает наиболее длительные ветви (содержащие либо часто вызываемые функции, либо функции, выполнявшиеся дольше остальных). Для демонстрации возможностей Quantify было сконструировано простое приложение, состоящее из функции «main» и двух дополнительных «recursive» и «outside» (см. листинг 1).
Листинг 1. Пример тестируемого приложения, сконструированном в виде консольного приложения из Visual Studio 6.0. Язык реализации «С».
#include "stdafx.h"
//Создаем функцию-заглушку
void outside (void)
{
static int v=0;
v++;
}
//Создаем рекурсивную функцию, исполняющуюся 100 раз
int recursive(void)
{
static int i=0;
int oo;
outside();//Вызываем функцию заглушку
if(i==100){i=1;return 0;}//Обнуляем счетчик и выходим
i++;
recursive();
}
int main(int argc, char* argv[])
{
int i;
for(i=0;i<100;i++)recursive();
//Вызываем 100 раз рекурсивную функцию 100х100
return 0;
}
Приложение простое по сути, но очень содержательное, так как эффективно демонстрирует основные возможности Quantify.
В самом начале статьи мы выдвигали требование, по которому разработчикам не рекомендуется пользоваться рекурсивными функциями.
Тестеры или разработчики, увидев диаграмму вызовов, выделят функцию, находящуюся в полукруге, что является признаком рекурсивного вызова (см. рисунок).

В зависимости от того, на какой из ветвей дерева, находится курсор, выводится дополнительная статистическая информация о временном доступе к выделенной функции и к дочерним, идущим ниже.
Следующий рисунок демонстрирует статистику по функции «recursive».
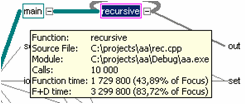
Более подробно о статистике будет рассказано в следующем материале.
Список вызовов функций «Function List»
к оглавлениюОдно из наиболее важных статистических окон. Здесь в табличном виде выводится статистическая информация по числу и времени работы каждой функции. Рисунок 6 демонстрирует окно с включенной сортировкой по числу вызовов каждой функции. В качестве дополнительной информации включен список формальных параметров вызовов функций. Подобную информацию можно получить только в том случае, когда тестируется модуль с отладочным кодом, к которому прилагается исходный текст.
Единицы измерения длительности работы функций могут быть следующими:
- Микросекунды;
- Миллисекунды;
- Секунды;
- Машинные циклы.
На рисунке приведены цифры соответствующие машинным циклам.

Полученная таблица вызовов анализируется тестером или разработчиком для выяснения узких мест в производительности приложения.
К сожалению, для принятия решения о производительности приложения, а точнее, производительности отдельных его функций можно принимать только рассматривая данный вопрос в комплексном разрезе. А именно, принимается во внимание и число вызовов каждой функции, и среднее время доступа к функции и общее время работы функции, и, наконец, то использовались ли при компиляции определенные специфические настройки компилятора.
Это комплексный подход, не предполагающий однозначного совета.
Сначала рассмотрим описание столбцов в появившейся таблице. Хотя многие из пунктов и являются интуитивно понятными, все же попробуем дать им короткое описание:
- Function. Наименование функции. Можно высвечивать число и тип формальных параметров вызова данной функции.
- Calls. Число вызовов. Величина абсолютная.
- Function Time. Общее время исполнения всех вызовов данной функции
- Max F Time. Максимальное время функции
- Module. Полный путь до модуля с функцией (бинарного)
- Min F Time. Минимальное время работы функции
- Source File. Полный путь до исходных текстов модуля.
По любому из предложенных полей можно провести сортировку в прямом и обратном порядке, а также наложить фильтр на определенные модули, например, для проверки только внутренних модулей или только внешних.
Выделить из списка узкую функцию трудно, поскольку для правильного расчета нужно принимать во внимание и время работы функции и число вызовов. Причем, число вызовов не всегда может быть показателем медлительности функции (вызывается часто, а работает быстро).
Трудно давать какие либо советы по оптимизации кода, тем более, что в этой редакции мы не ставили перед собой подобных целей. По теории оптимизации написаны громадные труды, к которым мы с радостью и отправляем читателей.
Можно, конечно, дать общие рекомендации по улучшению производительности кода и его эффективности:
Использовать конструкцию «I++» вместо «I=I+1», так как компиляторы транслируют первую конструкцию в более эффективный код. К сожалению, этот эффективность примера ограничена настройками используемого компилятора, и иногда бывает равнозначной по быстродействию;
Использовать прием развертывания циклов. Такой же старый прием оптимизации работы относительно простых циклов. Эффект заключается в сокращении числа проверок условия счетчика, так при проверке выполняются очень медленные функции микропроцессора (функции перехода). То есть вместо кода:
For(i=0;i<100;i++)sr=sr+1;
Лучше писать:
For(i=0;i<100;i+=2)
{
sr++;
sr++;
}
Использовать тактику отказа от использования вычисляющих конструкций внутри простых циклов. То есть, если иметь подобный фрагмент кода:
for (sr = 0; sr < 1000; sr++)
{
a[sr] = x * y;
}
то его лучше преобразовать в такой:
mn= x * y;
for (sr = 0; sr < 1000; sr++)
{
a[sr] = mn;
}
поскольку мы избавляемся от лишней операции умножения в простом цикле;
Там где возможно при работе с многомерными массивами, обращаться с ними как с одномерными. То есть, если есть необходимость в копировании или инициализации, например, двумерного массива, то вместо кода:
int sr[400][400];
int j, i;
for (i = 0; i < 400; i++)
for (j = 0; j < 400; j++)
sr[j][i] = 0;
лучше использовать конструкцию, в которой нет вложенного цикла:
int sr[400][400];
int *p = &sr[0][0];
for (int i = 0; i < 400*400; i++)
p[sr] = 0; // или *p++=0, что для большинства компиляторов одно и тоже
Также при работе с циклами выгодно использовать слияния, когда несколько коротких однотипных циклов сливаются вместе. Подобный подход также дает прирост в производительности кода;
В математических приложениях, требующих больших вычислений с плавающей точкой, или с большим количеством вызовов тригонометрических функций, удобно не производить все вычисления непосредственно, а использовать подготовленные значения в различных таблицах, обращаясь к ним как к индексам в массиве. Подход очень эффективен, но, к сожалению, как и многие эффективные подходы применим не всегда;
Короткие функции в классах лучше оформлять встроенными (inline);
В строковых операциях, в операциях копирования массивов лучше пользоваться не собственными функциями, а применять для этого стандартные библиотеки компилятора, так как эти функции, как правило, уже оптимизированы по быстродействию;
Использовать команды SSL и MMX, поскольку в достаточно большом круге задач они способны дать ускорение работы приложений в разы. Под такие задачи попадают задачи по работе с матрицами и векторами (арифметические операции над матрицами и векторами);
Использовать инструкции сдвига вместо умножений и делений там, где это позволяет делать логика программы. Например, инструкция S=S<<1 всегда эффективнее, чем S=S*2;
Конечно, это далеко не полный список приемов оптимизации кода по производительности и качеству. Для этого есть масса других книг. Примеры здесь имеют чисто утилитарный подход: демонстрация возможностей Quantify в плане исследования временных характеристик кода.
Используя все средства сбора и отображения, разработчик постепенно сможет использовать только эффективные конструкции, что поднимет производительность на недосягаемую ранее высоту.
По любой функции можно вывести более детальный отчет (см. рисунок). Из него можно почерпнуть информацию о числе дочерних функций и то, откуда они были произведены. Следующий рисунок демонстрирует данную возможность.

Переход к просмотру исходного текста.
Если тестируемый модуль сопровождается исходным текстом, то в Quantify имеется возможность по переходу на уровень просмотра исходного текста. По контекстному меню можно осуществить данный переход. Вызывать функцию перехода имеет смысл только в том случае, когда Quantify работает в независимом режиме, в отрыве от среды разработки. Рисунок демонстрирует данный режим.
Сравнивание запусков «Compare Runs»
к оглавлениюВ большинстве случаев требуется иметь не только сведения об отдельных запусках, но и сравнения разных запусков в различных комбинациях для прогнозирования и анализа. Ведь всегда интересно знать быстро работает исправленная функция или медленно, по сравнению с тем, что было до этого.
Подобная аналитическая информация позволить иметь достаточно четкое представление о том находятся ли функции в прогрессирующем или в регрессирующем состоянии.
Для вызова модуля сравнения необходимо воспользоваться кнопкой (Compare Runs), выделив один из запусков, и указав на любой другой (каждый новый запуск отображается в истории запусков на левой части рабочего поля Quantify).
Для осуществления не пустого сравнения, в пример, рассмотренный выше, намеренно были внесены изменения, увеличившие число вызовов функций. Данные были сохранены и перекомпилированы и снова исполнены в Quantify. Результат представлен на рисунке:

Сравнение запусков позволяет проводить сравнительный анализ между базовым запуском (base – том, с которого все началось) и новым (new).
Результаты сравнения также остаются в проекте Quantify и сохраняются на протяжении жизненного цикла разработки проектов.
Наравне со сравнением запуск можно воспользоваться суммированием, нажав на кнопку ![]() . Эта функция вызывает простое суммирование чисел от двух запусков.
. Эта функция вызывает простое суммирование чисел от двух запусков.
Можно сравнивать и складывать также запуски вместе со слепками (snapshot), которые позволяют оформить текущее количественное состояние в работе приложения в виде отдельного запуска. В дальнейшем над ним можно провести любую логическую операцию.
Ценность слепков проявляется тогда, когда необходимо узнать число вызовов каждой функции до свершения определенного события, например, до входа в определенный пункт меню в тестируемом приложении.
API
к оглавлениюЭто дополнительная возможность, предоставляемая Quantify по полному управлению процессом тестирования. API представляет собой набор функций, которые можно вызывать из тестируемого приложения по усмотрению разработчика.
Для получения доступа к API необходимо выполнить ряд действий по подключению «puri.h» файла с определением функций и с включением «pure_api.c» файла в состав проекта. Единственное ограничение, накладываемое API — рекомендации по постановке точек останова после вызовов Quantify при исполнении приложения под отладчиком.
Рассмотрим имеющиеся функции API Quantify:
- QuantifyAddAnnotation. Позволяет задавать словесное описание, сопровождающее тестирование кода. Информация, заданная разработчиком этой функцией может быть извлечена из пункта «details» меню тестирования и доступна в LOG-файле. На ее основе, тестер может впоследствии использовать особые условия тестирования;
- QuantifyClearData. Очищает все несохраненные данные;
- QuantifyDisableRecordingData. Запрещает дальнейшую запись;
- QuantifyIsRecordingData. Возвращает значение 1 или 0 в зависимости от того производится ли запись свойств или нет;
- QuantifyIsRunning. Возвращает значение 1 или 0 в зависимости от того проходит тестируемое приложение исполнение в обычном режиме или под Quantify;
- QuantifySaveData. Данная функция позволяет сохранять текущее состояние — делать снимок (snapshot);
- QuantifySetThreadName. Функция позволяет разработчикам именовать потоки в произвольном именном поле. По умолчанию Quantify дает имена, наподобие «thread_1», что может не всегда положительно сказываться на читаемости получаемой информации;
- QuantifyStartRecordingData. Начинает запись свойств. По умолчанию, данная функция автоматически вызывается Quantify при исполнении;
- QuantifyStopRecordingData. Останавливает запись свойств.
Если модифицировать наше тестовое приложение так, чтобы оно использовало преимущества интерфейса API, то может получиться нечто нижеследующее
int main(int argc, char* argv[])
{
int i;
QuantifyAddAnnotation("Тестирование проводится под Quantify с использованием API");
QuantifySetThreadName("Основной поток приложения");
for(i=0;i<12;i++){
QuantifySaveData();
recursive();
}
return 0;
}
В листинге показано как можно использовать основные функции API для извлечения максимального статистического набора данных.
Рисунки показывают слепки фрагментов экрана Quantify по окончании тестирования.
Рис. Данный рисунок демонстрирует вид окна после выполнения команды снятия слепка или вызова функции API QuantifySaveData()

Рис. Обратите внимание на поле аннотации

Рис. У Quantify отсутствуют сложности с русскими буквами
Сохранение данных и экспорт | к оглавлению
Традиционные операции над файлами присущи и программе Quantify. Дополнительные особенности заключаются в том, что сохранять данные можно как во встроенном формате (qfy), для каждого отдельного запуска, так и в текстовом виде, для последующего использования в текстовых редакторах, либо для дальнейшей обработки скриптовыми языками типа perl (более подробно смотрите об этом в разделах по ClearCase и ClearQuest).
Quantify позволит переносить таблицы через буфер обмена в Microsoft Excel, что открывает безграничные возможности по множественному сравнению запусков, по построению графиков и различных форм. Все что необходимо сделать — это только скопировать данные из одной программы и поместить в другую известным способом.
Purify. Контроль над утечками памяти
Введение
к оглавлениюНачать описание возможностей продукта Rational Purify хочется перефразированием одного очень известного изречения: «с точностью до миллиБАЙТА». Данное сравнение не случайно, ведь именно этот продукт направлен на разрешение всех проблем, связанных с утечками памяти. Ни для кого не секрет, что многие программные продукты ведут себя «не слишком скромно», замыкая на себя во время работы все системные ресурсы без большой на то необходимости. Подобная ситуация может возникнуть вследствие нежелания программистов доводить созданный код «до ума», но чаще подобное происходит не из за лени, а из-за невнимательности. Это понятно — современные темпы разработки ПО в условиях жесточайшего прессинга со стороны конкурентов не позволяют уделять слишком много времени оптимизации кода, ведь для этого необходимы и высокая квалификация, и наличие достаточного количества ресурсов проектного времени. Как мне видится, имея в своем распоряжении надежный инструмент, который бы сам в процессе работы над проектом указывал на все черные дыры в использовании памяти, разработчики начали бы его повсеместное внедрение, повысив надежность создаваемого ПО. Ведь и здесь не для кого не секрет, что в большинстве сложных проектов первоочередная задача, стоящая перед разработчиками заключается в замещении стандартного оператора «new» в С++, так как он не совсем адекватно себя ведет при распределении памяти.
Вот на создании\написании собственных велосипедов и позволит сэкономить Purify.
Рисунок демонстрирует внешний вид программы после проведения инструментирования (тестирования) программного модуля.
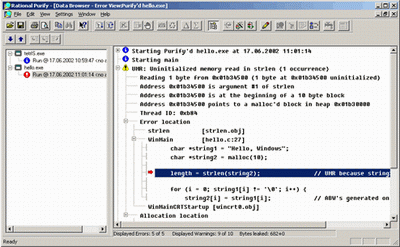
Общие возможности по управлению Purify схожи с Quantify, за исключением специфики самого продукта. Здесь также можно тестировать многопоточные приложения, также можно делать «слепки» памяти во время тестирования приложения.
Особенности использования данного приложения касаются спецификой отлавливаемых ошибок и способом выдачи информации.
Информация выдается в виде списке, с наименованием найденной ошибки или предупреждения. При разворачивании списка с конкретной ошибкой выводится дополнительный набор данных, характеризующих ошибку.
Основные параметры вывода | к оглавлению
- Address. IP адрес модуля, в котором обнаружена ошибка или предупреждение;
- Error Location. Описание модуля с ошибкой. В случае тестирования модуля с исходными текстами, то в данном поле можно просмотреть фрагмент кода, который вызвал появление ошибки;
- Allocate Location. Разновидность «Error Location», показывает фрагмент кода, в котором был распределен блок памяти, работа с которым, привела к ошибке.
Работа с Purify возможна как при наличии исходных текстов и отладочной информации, так и без нее. В случае отсутствия debug-информации анализ ошибок ведется только по ip-адресам. Так же как и в случае с Quantify, возможен детальный просмотр функций из dll-библиотек. В этом случае наличие отладочной информации не является необходимостью.
Сообщения об ошибках и предупреждениях
к оглавлениюДля того, чтобы иметь представление о возможностях продукта, опишем то, какие ошибки и потенциальные ошибки могут присутствовать в тестируемом приложение.
Отметим разницу между ошибкой и потенциальной ошибкой и опишем:
-
Ошибка — свершившийся факт нестабильной или некорректной работы приложения, проводящий к неадекватным действиям приложения или системы. Примером подобной ошибки можно считать выход за пределы массива или попытка записи данных по 0 адресу;
-
Потенциальная ошибка — в приложении имеется фрагмент кода, который при нормальном исполнении не приводит к ошибкам. Ошибка возникает только в случае стечения обстоятельств, либо не проявляет себя никогда. К данной категории можно отнести такие особенности, как инициализация массива с ненулевого адреса, скажем, имеется массив на 100 байт, но каждый раз обращение к нему производится с 10 элемента. В этом случае Purify считает, что имеется потенциальная утечка памяти размером в 10 байт.
Естественно, что подобное поведение может быть вызвано спецификой приложения, например, так вести себя может текстовый редактор. Поэтому в Purify применятся деление информации на ошибки и потенциальные ошибки (которые можно воспринимать как специфику).
Список ошибок и потенциальных ошибок достаточно объемен и постоянно пополняется. Кратко опишем основные сообщения, выводимые после тестирования:
- Array Bounds Read Выход за пределы массива при чтении;
- Array Bounds Write Выход за пределы массива при записи;
- Late Detect Array Bounds Write Cообщение указывает, что программа записала значение перед началом или после конца распределенного блока памяти;
- Beyond Stack Read Сообщение указывает, что функция в программе собирается читать вне текущего указателя вершины стека;
- Freeing Freed Memory Попытка освобождения свободного блока памяти;
- Freeing Invalid Memory Попытка освобождения некорректного блока памяти;
- Freeing Mismatched Memory Сообщение указывает, что программа пробует;
- Free Memory Read Попытка чтения уже освобожденного блока памяти;
- Free Memory Write Попытка записи уже освобожденного блока памяти;
- Invalid Handle Операции над неправильным дескриптором;
Handle In Use Индикация утечки ресурсов. Неправильная индикация дескриптора; - Invalid Pointer Read\Write Ошибка при чтении\записи из недоступного блока памяти;
- Memory Allocation Failure Ошибка в запросе на распределение памяти;
- Memory Leak Утечка памяти;
- Potential Memory Leak Потенциальная утечка памяти;
- Null Pointer Read Попытка чтения с нулевого адреса;
- Null Pointer Write Попытка записи в нулевой адрес;
- Uninitialized Memory Copy Попытка копирования непроинициализированного блока;
- UMR: Uninitialized Memory Read Попытка чтения непроинициализированного блока.
Предупреждения и ошибки удобно группировать по определенным признакам, чтобы легче можно было отыскать нужное предупреждение и отбросить ненужные.
Отметим категории и принадлежность к ним различных сообщений:
- Allocation and deallocation. Работа с памятью;
- DLL messages. Информационные сообщения по внешним библиотекам;
- Invalid handles. Неправильный дескриптор;
- Invalid pointers. Неправильный указатель;
- Memory leaks. Утечка памяти;
- Parameter errors. Ошибка параметра;
- Stack errors. Ошибка при работе со стеком;
- Unhandled exception. Исключение;
- Uninitialized memory. Использование непроинициализированного блока памяти.
Многие статические ошибки могут вылавливать компиляторы на этапе разработки программного модуля или приложения. На этом этапе преимущества Purify не очень видны.
Все механизмы анализа ошибок открываются при исполнении приложения, при динамически меняющихся условиях.
Рассмотрим более подробно список отлавливаемых ошибок, определив их принадлежность к категориям с примерами на C++/C:
ABR: Array Bounds Read. Выход за пределы массива при чтении.
Известная болезнь всех разработчиков — неправильно поставленное условие в цикле. Соответственно, ошибка, которая имеет место быть в программе, связанная с чтением лишней информации, может проявить себя, а может и не проявить. Но она является потенциальной ошибкой.
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *ptr = new char[5];//Выделяем память под массив из 5 символов
ptr[0] = ‘e’;
ptr[1] = ‘r’;
ptr[2] = ‘r’;
ptr[3] = ‘o’;
ptr[4] = ‘r’;
for (int i=0; i <= 5; i++) {
//Ошибка, при i=5 – выход за пределы массива
cerr << "ptr[" << i << "] == " << ptr[i] << '\n';
}
delete[] ptr;
return(0);
}
ABW: Array Bounds Write. Выход за пределы массива при записи
Вероятность того, что приложение может неадекватно вести себя из-за данной ошибки более высоко, так как запись по адресу, превышающим размер блока, вызывает исключение.
Отметим, что память можно определить статически, массовом, как показано в примере. А можно динамически (например, выделив блок памяти по ходу исполнения приложения).
По умолчанию, Purify успешно справляется только с динамическим распределением, четко выводя сообщение об ошибке. В случае статического распределения, все зависит от размеров «кучи» и настроек компилятора.
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char * ptr = new char[5];//Выделяем память под массив из 5символов
for (int i=0; i <= 5; i++) {
//Ошибка, при i=5 - выход за пределы массива
ptr[i] = ‘!’;
cerr << "ptr[" << i << "] == " << ptr[i] << '\n'; //ABW + ABR when i is 5
}
delete[] ptr;
return(0);
}
ABWL: Late Detect Array Bounds Write. Cообщение указывает, что программа записала значение перед началом или после конца распределенного блока памяти
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char * ptr = new char[5];//Выделяем память под массив из 5 символов
for (int i=0; i <= 5; i++) {
//Ошибка – попытка записи после блока выделенной памяти
ptr[i] = ‘!’;
cerr << "ptr[" << i << "] == " << ptr[i] << '\n';
}
delete[] ptr; //ABWL: ОШИБКА
return(0);
}
BSR: Beyond Stack Read. Сообщение указывает, что функция в программе собирается читать вне текущего указателя вершины стека
Категория: Stack Error
#include <windows.h>
#include <iostream.h>
#define A_NUM 100
char * create_block(void)
{
char block[A_NUM];//Ошибка: массив должен быть статическим
for (int i=0; i < A_NUM; i++) {
block[i] = ‘!’;
}
return(block);//Ошибка: неизвестно, что возвращать
}
int main(int, char **)
{
char * block;
block = create_block();
for (int i=0; i < A_NUM; i++) {
//BSR: нет гарантии, что элементы из "create_block" до сих пор находятся в стеке
cerr << "element #" << i << " is " << block[i] << '\n';
}
return(0);
}
FFM: Freeing Freed Memory. Попытка освобождения свободного блока памяти.
В большом приложении трудно отследить момент распределения блока и момент освобождения. Очень часто методы реализуются разными разработчиками, и, соответственно, возможна ситуация, когда распределенный блок памяти освободается дважды в разных участках приложения.
Категория: Allocations and deallocations
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *ptr1 = new char;
char *ptr2 = ptr1;//Ошибка: должен дублировать объект, а не копировать указатель
*ptr1 = ‘a’;
*ptr2 = ‘b’;
cerr << "ptr1" << " is " << *ptr1 << '\n';
cerr << "ptr2" << " is " << *ptr2 << '\n';
delete ptr1;
delete ptr2;//Ошибка – освобождение незанятой памяти
return(0);
}
FIM: Freeing Invalid Memory. Попытка освобождения некорректного блока памяти.
Разработчики часто путают простые статические значения и указатели, пытаясь освободить то, что не освобождается. Компилятор не всегда способен проанализировать и нейтрализовать данный вид ошибки.
Категория: Allocations and deallocations
#include <iostream.h>
int main(int, char **)
{
char a;
delete[] &a;//FIM: в динамической памяти нет объектов для уничтожения
return(0);
}
FMM: Freeing Mismatched Memory. Сообщение указывает, что программа пробует освобождать память с неправильным ВЫЗОВОМ API для того типа памяти
Категория: Allocations and deallocations
#include <windows.h>
int main(int, char **)
{
HANDLE heap_first, heap_second;
heap_first = HeapCreate(0, 1000, 0);
heap_second = HeapCreate(0, 1000, 0);
char *pointer = (char *) HeapAlloc(heap_first, 0, sizeof(int));
HeapFree(heap_second, 0, pointer);
//Ошибка – во второй куче не выделялась память
HeapDestroy(heap_first);
HeapDestroy(heap_second);
return(0);
}
FMR: Free Memory Read. Попытка чтения уже освобожденного блока памяти
Все та же проблема с указателем. Блок распределен, освобожден, а потом, в ответ на событие, по указателю начинают записываться (или читаться) данные.
Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *ptr = new char[2];
ptr[0] = ‘!’;
ptr[1] = ‘!’;
delete[] ptr;//Ошибка – освобождение выделенной памяти
for (int i=0; i < 2; i++) {
//FMR: Ошибка- попытка чтения освобождённой памяти
cerr << "element #" << i << " is " << ptr[i] << '\n';
}
return(0);
}
FMW: Free Memory Write. Попытка записи уже освобожденного блока памяти
Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *ptr = new char[2];
ptr[0] = ‘!’;
ptr[1] = ‘!’;
delete[] ptr;//специально освобождаем выделенную память
for (int i=0; i < 2; i++) {
ptr[i] *= ‘A’; //FMR + FMW: память для *ptr уже освобождена
cerr << "element #" << i << " is " << ptr[i] << '\n'; //FMR
}
return(0);
}
HAN: Invalid Handle. Операции над неправильным дескриптором
Категория: Invalid handles
#include <iostream.h>
#include <windows.h>
#include <malloc.h>
int main(int, char **)
{
int i=8;
(void) LocalUnlock((HLOCAL)i);//HAN: i – не является описателем объекта памяти
return(0);
}
HIU: Handle In Use. Индикация утечки ресурсов. Неправильная индикация дескриптора.
#include <iostream.h>
#include <windows.h>
static long GetAlignment(void)
{
SYSTEM_INFO desc;
GetSystemInfo(&desc);
return(desc.dwAllocationGranularity);
}
int main(int, char **)
{
const long alignment = GetAlignment();
HANDLE handleToFile = CreateFile("file.txt",
GENERIC_READ|GENERIC_WRITE, 0, NULL, CREATE_ALWAYS,
FILE_ATTRIBUTE_NORMAL, NULL);
if (handleToFile == INVALID_HANDLE_VALUE) {
cerr << "Ошибка открытия, создания файла\n";
return(1);
}
HANDLE handleToMap = CreateFileMapping(handleToFile, NULL, PAGE_READWRITE, 0, alignment, "mapping_file");
if (handleToMap == INVALID_HANDLE_VALUE) {
cerr << "Unable to create actual mapping\n";
return(1);
}
char * ptr = (char *) MapViewOfFile(handleToMap, FILE_MAP_WRITE, 0, 0, alignment);
if (ptr == NULL) {
cerr << "Unable to map into address space\n";
return(1);
}
strcpy(ptr, "hello\n");
//HIU: handleToMap до сих пор доступен и описывает существующий объект
return(0);
}
IPR: Invalid Pointer Read. Ошибка обращения к памяти, когда программа пытается произвести чтение из недоступной области
Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char * pointer = (char *) 0xFFFFFFFF;
//Ошибка - указатель на зарезервированную область памяти
for (int i=0; i < 2; i++) {
//IPR: обращение к зарезервированной части адресного пространства
cerr << "pointer[" << i << "] == " << pointer[i] << '\n';
}
return(0);
}
IPW: Invalid Pointer Write. Ошибка обращения к памяти, когда программа пытается произвести запись из недоступной области
Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *pointer = (char *) 0xFFFFFFFF;
//Ошибка - указатель на зарезервированную область памяти
for (int i=0; i < 2; i++) {
//IPW + IPR: обращение к зарезервированной части адресного пространства
pointer[i] = ‘!’;
cerr << "ptr[" << i << "] == " << ptr[i] << '\n';
}
return(0);
}
MAF: Memory Allocation Failure. Ошибка в запросе на распределение памяти. Возникает в случаях, когда производится попытка распределить слишком большой блок памяти, например, когда исчерпан файл подкачки.
Категория: Allocations and deallocations
#include <iostream.h>
#include <windows.h>
#define BIG_BLOCK 3000000000 //размер блока
int main(int, char **)
{
char *ptr = new char[BIG_BLOCK / sizeof(char)];
//MAF: слишком большой размер для распределения
if (ptr == 0) {
cerr << "Failed to allocating, as expected\n";
return (1);
} else {
cerr << "Got " << BIG_BLOCK << " bytes @" << (unsigned long)ptr << '\n';
delete[] ptr;
return(0);
}
}
MLK: Memory Leak. Утечка памяти
Распространенный вариант ошибки. Многие современные приложения грешат тем, что не отдают системе распределенные ресурсы по окончании своей работы.
Категория: Memory leaks
#include <windows.h>
#include <iostream.h>
int main(int, char **)
{
(void) new int[1000];
(void) new int[1000];
//результат потери памяти
return(0);
}
MPK: Potential Memory Leak. Потенциальная утечка памяти
Иногда возникает ситуация, в которой необходимо провести инициализацию массива не с нулевого элемента. Purify считает это ошибкой. Но разработчик, пишущий пресловутый текстовый редактор может инициализировать блок памяти не с нулевого элемента.
Категория: Memory leaks
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
static int *pointer = new int[100000];
pointer += 100;//MPK: потеряли начало массива
return(0);
}
NPR: Null Pointer Read. Попытка чтения с нулевого адреса
Бич всех программ на С\С++. Очень часто себя ошибка проявляет при динамическом распределении памяти приложением, так как не все разработчики ставят условие на получение блока памяти, и возникает ситуация, когда система не может выдать блок указанного размера и возвращает ноль. По причине отсутствия условия разработчик как не в чем не бывало начинает проводить операции над блоком, адрес в памяти которого 0.
Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int
main(int, char **)
{
char * pointer = (char *) 0x0; //указатель на нулевой адрес
for (int i=0; i < 2; i++) {
//NPR: попытка чтения с нулевого адреса
cerr << "pointer[" << i << "] == " << pointer[i] << '\n';
}
return(0);
}
NPW: Null Pointer Write. Попытка записи в нулевой адрес
Категория: Invalid pointers
#include <iostream.h>
#include <windows.h>
int
main(int, char **)
{
char * pointer = (char *) 0x0; //указатель на нулевой адрес
for (int i=0; i < 2; i++) {
//NPW: ошибка доступа
pointer[i]=’!’;
cerr << "pointer[" << i << "] == " << pointer[i] << '\n';
}
return(0);
}
UMC: Uninitialized Memory Copy. Попытка копирования непроинициализированного блока памяти
Категория: Unitialized memory
#include <iostream.h>
#include <windows.h>
#include <string.h>
int main(int, char **)
{
int * pointer = new int[10];
int block[10];
for (int i=0; i<10;i++)
{
pointer[i]=block[i]; //UMC предупреждение
cerr<<block[i]<<”\n”;
}
delete[] pointer;
return(0);
}
UMR: Uninitialized Memory Read. Попытка чтения непроинициализированного блока памяти
Категория: Unitialized memory
#include <iostream.h>
#include <windows.h>
int main(int, char **)
{
char *pointer = new char;
cerr << "*pointer is " << *pointer << '\n';
//UMR: pointer указывает на непроинициализированный элемент
delete[] pointer;
return(0);
}
Работа с фильтром
к оглавлениюЧтобы не загромождать пользовательский интерфейс лишними данными, в Purify предусмотрена система гибких фильтров.
Система фильтров Purify способна регламентировать тип ошибок и предупреждений и ошибок (группировка производится по категориям) к программе, но и число исследуемых внешних модулей (чтобы разработчик мог концентрироваться только на ошибках собственного модуля). Таким образом возможно создание универсальных фильтров с осмысленными именами, которые ограничивают поток информации. Число создаваемых фильтров ничем не ограничено.
Фильтры создаются и назначаются и модифицируются через верхнее меню (View->CreateFilter и View->FilterManager). По умолчанию Purify выводит все сообщения и предупреждения.
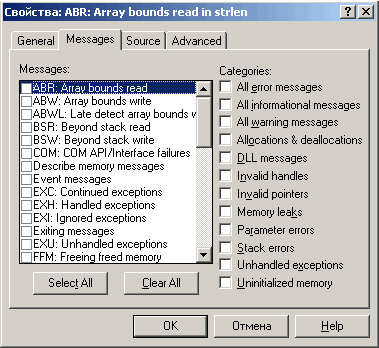
Рисунок показывает внешний вид окна создания фильтра (View->CreateFilter). Здесь мы имеем возможность по выбору сообщений, которые нужно отфильтровывать.
Пункт General — управляет именем фильтра и комментарием, его сопровождающим, Source — определяет местоположение исходных файлов, для которых необходимо вывести сообщения. Подход используется в том случае, когда происходит вызов одного модуля из другого, дабы ограничить количество информации в отчете.
Следующий рисунок демонстрирует вид окна настроек фильтров. Здесь имеется возможность по активации\деактвации фильтров и модулей.
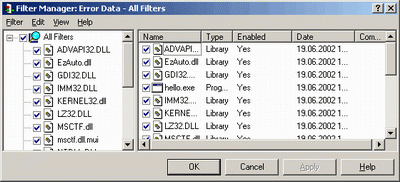
Выше упоминалось, что Purify не ограничивает число фильтров. Следует понимать, что не ограничивается не только общее число фильтров, но и их количество на одно протестированное приложение.
Ограничение по модулям, которое также можно выставить в данном диалоге, определяет число внешних модулей, предупреждения от которых появляются в отчете.
API | к оглавлению
Rational Purify также имеет ряд функций интерфейса, воздействуя на которые, разработчик на этапе создания приложения может пользоваться всеми благами, предоставляемые данным приложением.
Опишем основные функции интерфейса с краткой характеристикой, разделив предварительно все функции по основным группам:
Функции установки статуса распределенных блоков:
- PurifyMarkAsInitialized. Устанавливает пометку на указанный блок, делая его помеченным, как проинициализированный;
- PurifyMarkAsUninitialized. Ставит флаг инициализации;
Функции тестирования состояний распределенных блоков
- PurifyAssertIsReadable. Проверяет, доступен ли блок памяти для чтения;
- PurifyAssertIsWritable. Проверяет, доступен ли блок памяти для чтения;
- PurifyIsInitialized. Проверяет, проинициализирован блок памяти или нет;
- PurifyIsReadable. Проверяет блок памяти на возможность чтения;
- PurifyIsWritable. Проверяет блок памяти на возможность записи;
Функции, определяющие разрушения
- PurifySetLateDetectScanCounter. Определяет счетчик сканирования кучи. Подсчитывает число операций. По умолчанию, Purify сканирует память через каждые 200 операций с памятью, либо каждые 10 секунд;
- PurifySetLateDetectScanInterval. Определяет временной интервал сканирования кучи. По умолчанию — 10 секунд;
PurifyHeapValidate. Принудительно проверяет память на наличие ошибок;
Функции, определяющие утечки памяти
- PurifyAllInuse. Возвращает значение, определяющее количество занятой памяти;
- PurifyClearInuse. Возвращает значение, показывающее количество памяти, распределенное после последнего вызова PurifyClearInuse или PurifyNewInuse;
- PurifyAllLeaks. Возвращает число найденных утечек в памяти. Находит как прямые утечки памяти, так и косвенные;
- PurifyClearLeaks. Определяет число освобожденных блоков памяти за время последнего обращения к PurifyClearLeaks или PurifyAllLeaks;
- PurifyNewLeaks. Определяет число новых утечек памяти за время последнего обращения к PurifyNewLeaks или PurifyClearLeaks.
Сохранение данных и экспорт
к оглавлениюPurify позволяет сохранять результаты тестирования (file->save copy as) в четырех различных представлениях, позволяющих наиболее эффективным образом получить информацию о ходе тестирования.
Рассмотрим варианты сохранения:
- Purify Error unfiltered. Сохраняет данные о тестировании в виде «как есть» без фильтров;
- Purify error filtered. Сохраняет данные о тестировании с примененными фильтрами;
- Text expended. Сохраняет данные в текстовом виде о тестировании в расширенном представлении (с выводом найденных ошибок, с кратким описанием);
- Text view. Сохраняет только упоминание о найденных ошибках, без дополнительного описания
При установленном MS Outlook, возможно отправление отчета почтой через пункт file->send из верхнего меню Purify.
Параметры тестирования
к оглавлениюПеред исполнением тестируемого приложения, возможно, задать дополнительные настройки, которые смогут настроить Purify на эффективное тестирование.
Запуск приложения производится точно также как и в случае с Quantify (по F5 или file->Run). Параметры настройки находятся пункте Settings, появившегося окна.
Первая страница диалога представлена на рисунке

Отметим основные особенности, которые качественно могут сказаться на результирующем отчете:
- Report at exit. Данная группа позволяет получать более детальную информацию обо всех указателях и блоках памяти, которые не приводили к ошибкам памяти. По умолчанию, Purify выводит отчеты только по тем блокам, которые были распределены, но не были освобождены. В большинстве случаев такой подход оправдан, так как обычно разработчика интересуют именно ошибки. Остальные пункты активизируют по мере необходимости, когда нужно иметь общее представление о использовании памяти тестируемым приложением;
- Error Suppretion. Группа определяет степенью детальности выводимой информации.
По умолчанию, активирован пункт «Show first message only». В этом случае по окончании тестирования, Purify выводит сокращенный отчет по модулям, то есть, если в одном модуле найдено 10 утечек памяти, то информация об утечках на основном экране будет описывать только имя ошибки, число блоков и имя модуля. То есть мы получаем обобщенную информацию по ошибкам в блоке. В случае необходимости получения отдельного отчета по каждому отдельному блоку, отключаем данный пункт. - Call Stack Length. Определяет глубину стека;
- Red Zone Length. Управляет числом байтов, которое встраивается в код тестируемого приложения при операциях связанных с распределением памяти. Увеличение числа способствует лучшему сбору информации, но существенно тормозит исполнение приложения;
Закладка PowerCheck позволит настроить уровень анализа каждого отдельно взятого модуля. Существует два способа инструментирования тестируемого приложения: Precise и Minimal. В первом случае проводится детальное инструментирование кода, но при этом модуль работает относительно медленно. Во втором случае, проводится краткое инструментирование, при котором Purify вносит в модуль меньше отладочной информации, и, как следствие, способна отловить меньшее число ошибок. Последний подход оправдан, когда приложение вызывает массу внешних библиотек от третьих фирм, которые не будут подвергаться правке.
PureCoverage. Проверка области охвата кода
Введение
к оглавлениюОсновное назначение продукта — выявление участков кода, пропущенного при тестировании приложения — проверка области охвата кода.
Очевидно, что при тестировании разработчику или тестировщику не удастся проверить работоспособность абсолютно всех функций. Также невозможно за один проход тестирования исполнить приложение с учетом всех условных ветвлений.
По требованиям на разработку программного кода, программист должен предоставить для функционального тестирования стабильно работающее приложение или модуль, без утечек памяти и полностью протестированный.
Понятие «полностью протестированный» определяет руководство компании в числовом, процентном значении. То есть, при оформлении требований указано, что область охвата кода 70%. Соответственно, по достижении данной цифры дальнейшие проверки кода можно считать нецелесообразными. Конечно, вопрос области охвата, очень сложный и неоднозначный. Единственным утешением может служить то, что 100% области охвата в крупных проектах не бывает.
Из трех рассматриваемых инструментов тестирования PureCoverage можно считать наиболее простым, так как информация им предоставляемая — это просмотр исходного текста приложения, где указано сколько раз исполнилась та или иная строка в приложении.
Особенности запуска | к оглавлению
Запуск приложения ведется точно таким же образом, как и в остальных случаях. Здесь нового ничего нет. Из особенностей можно отметить то, что тестировать можно только то приложение, которое содержит отладочную информацию. Данная особенность выделяет PureCoverage из линейки инструментов тестирования для разработчиков, которые могут тестировать как код с отладочной информацией, так и без нее.
При попытке исполнить приложение, не содержащее отладочной информации, на экран, по окончании тестирования, будет выведено сообщение об ошибке.
Работа с PureCoverage | к оглавлению
По принципу работы PureCoverage слегка напоминает Quantify: также подсчитывает количество вызовов функций. Правда, получаемая статистика не столь исчерпывающая как в Quantify (в визуальном отношении), но для проверки области охвата кода вполне и вполне пригодна.
Система отчетности представлена 4-я различными видами отчетов:
- Coverage Browser. Основное окно просмотра, позволяет просматривать протестированное приложение по модулям или по файлам. Выдает статистику о наличии пропущенных строк;
- Function List. Выдает отчет по функциям;
- Annotated Source. Переход к режиму просмотра исходного текста;
- Run Summary. Общая информация о протестированном приложении;
Анализ результатов тестирования | к оглавлению
На рисунке показана статистическая выкладка, выведенная Coverage по окончании тестирования приложения.

Поле Calls определяет число вызовов функции
Из полученной таблицы видна статистическая информация о том, какие строки и сколько раз исполнялись.
К особенностям работы PureCoverage отнесем тестирование только тех исполняемых файлов, которые уже имеют отладочную информацию от компилятора. Соответственно, тестирование стандартных приложений и библиотек данным продуктом невозможно. Впрочем, и не нужно. Особые преимущества инструмент демонстрирует при совместном тестировании с Robot при функциональном тестировании, подсчитывая строки исходных текстов в момент воспроизведения скрипта. Тем самым на выходе тестировщик (или разработчик) получает информацию о стабильности функциональных компонент, плюс, область покрытия кода (область охвата).

Поле %Lines Hit показывает процентное отношение протестированных строк кода для отдельной функции.

Вид окна перехода на уровень работы с исходным текстом. Из него видно, что PureCoverage ведет нумерацию строки и подсчитывает число исполнений каждой. Не исполнившиеся фрагменты подсвечиваются красным цветом (палитра может регулироваться пользователем)
API
к оглавлениюКак и Quantify с Purify, данный инструмент имеет функции расширения интерфейса. Рассмотрим их краткое описание.
- CoverageAddAnnotation. Позволяет добавить словесное описание, сопровождающее тестирование. Информация, заданная разработчиком этой функцией может быть извлечена из пункта «details» меню тестирования и доступна в LOG-файле. На ее основе, тестер может впоследствии использовать особые условия тестирования;
- CoverageClearData. Очищает несохраненные данные. Используется для обнуления (инициализации);
CoverageDisableRecordingData. Запрет на запись данных о ходе тестирования. Продолжение записи не возможно. Используется для завершения процесса тестирования; - CoverageIsRecordingData. Выясняет проводится ли процесс записи данных о ходе тестирования. Используется для определения текущего статуса;
- CoverageIsRunning. Определеяет, запущен ли интсрумент тестирования;
- CoverageSaveData. Сохранение тестовых данных. Используется для получения слепков. Обычно данную функцию удобно вызывать перед и после блока ветвления в программе;
- CoverageStartRecordingData. Начало процесса записи тестовых данных;
- CoverageStopRecordingData. Окончание процесса записи тестовых данных;
Сохранение данных и экспорт | к оглавлению
Данные из инструмента тестирования сохраняются в текстовом файле (как и в двух предыдущих случаях). Текстовый формат выдачи информации делает возможным включать различные обработчики отчетов основанные на скриптовых языках (например, при помощи Perl, можно «выудить» специфичные поля из текстового отчета и поместить их в средство документирования, получив отчет).
Пример фрагмента отчета приведен ниже:
CoverageData WinMain Function D:\xp\Rational\Coverage\Samples\hello.c D:\xp\Rational\Coverage\Samples\hello.exe 0 1 1 100.0 5 5 10 50.00 36 1
SourceLines D:\xp\Rational\Coverage\Samples\hello.c D:\xp\Rational\Coverage\Samples\hello.exe
LineNumber LineCoverage
18.1 0
23.1 0
26.1 0
26.1 0
27.1 0
27.1 0
PureCoverage также как и Quantify может переносить табличные данные в Microsoft Excel.
Итог | к оглавлению
Данный инструмент представляется наиболее простым из трех. Основное его отличие невозможность работы с приложениями, в которых отсутствует отладочная информация. Из достоинств отметим возможность одновременного запуска совместно с Purify, что позволяет получить отчеты по утечкам памяти и подсчет числа строк за один проход в тестировании, что существенно экономит время при отладке и тестировании.
Дополнительные возможности средств тестирования для разработчиков
Способы запуска
к оглавлениюВсе инструментальные средства могут работать на 3 уровнях исполнения:
- Исполнение из меню операционной системы. Используется в большинстве случаев, как разработчиками так и тестировщиками. Последними чаще, так как у тестировщиков может не быть среды разработки;
- Исполнение из среды разработки (если есть интеграция с конкретным средством). Применяется в тех случаях, когда инструмент имеет интеграцию со средством разработки. Представляется наиболее удобным вариантом работы для разработчиков;
- Исполнение из командной строки. Применяется в специфических ситуациях: при интеграции со средствами автоматизированного тестирования функционального интерфейса, а также при тестировании особых приложений (таких как сервисы Win32).
Тестирование сервисов Windows NT/2000/XP
к оглавлениюОдно из важных преимуществ перед конкурентами — возможность тестирования специальных приложений, таких как сервисы.
собенность работы заключается в том, что сервис нельзя запускать из среды разработки. Инструменты тестирования понимают это, и предлагают свое решение, по которому необходимо насытить код откомпилированного сервиса (с отладочной информацией) отладочной информацией (не запустив при этом). Полученные в результате файл зарегистрировать в качестве сервиса. Сделать это можно как из GUI так и из командной строки. Мы рассмотрим последовательность шагов для командной строки, демонстрируя ее возможности (в примере, используется ссылка на Purify, но вместо него подставить имя любого средства тестирования):
- Правильно настроить системные пути таким образом, чтобы из них были видны все директории Purify (особенно кеш: \Program Files\Rational\Purify), иначе процесс не пойдет на исполнение;
- Откомпилированный сервис нужно запустить Purify из командной строки следующим образом: purify /Run=no /Out=service_pure.exe service.exe. Как видно из параметров, Purify инструментирует файл service.exe, помещая его копию вместе с OCI в service_pure.exe. Все происходит без запуска;
- В ключе реестра \HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services необходимо поставить ссылку на кешированный файл (service_pure.exe);
- Во вкладке сервисов активировать пункт Allow Service to Interact with Desktop, выбрать режим запуска "manual".
По окончании действий, в зависимости от типа операционной системы, необходимо перезапустить сервис или перезагрузить компьютер и запустить сервис.
В момент старта сервиса инструмент тестирования запустится автоматически.
Поскольку специальные программные средства могут не иметь графической оболочки, то для их детальной проработки рекомендуется использование функций API из инструментов тестирования для разработчиков.
Основные свойства средств Purify, Quantify и PureCoverage
к оглавлению- Интегрируются со средствами функционального тестирования Robot, TestManager и Visual Test;
Интегрируются с ClearQuest, для документирования и отслеживания возникающих в процессе тестирования ошибок; - Выдают точную и детальную информацию о производительности приложения;
- Используют технологию OCI — Object Code Insertion, что позволяет детально отслеживать и вылавливать ошибки не только в разрабатываемом модуле, но и во внешних библиотека;
- Представляют комплексный дополнительный обзор данных по производительности, области охвата кода и по стабильности;
Имеют гибкая настройка в соответствии с потребностям разработчиков и тестировщиков; - Позволяют многократно тестировать приложение (по ходу разработки), отслеживать изменения для каждой перекомпиляции, формируя тем самым данные для последующего анализа;
- Интегрируются со средствами разработки (Visual Studio 6.0, Visual Studio .NET, Vis-ual Age For Java);
- Тестируют компоненты ActiveX, COM/DCOM и ODBC;
- Имеют интерфейс API, позволяющий дописывать разработчикам собственные для наиболее тщательного и эффективного тестирования.