Методы бикластеризации для анализа интернет-данных
Дмитрий Игнатов,
кафедра анализа данных и искусственного интеллекта ГУ-ВШЭ
5.3. Формирование бикластеров для рекомендательной системы Интернет-рекламы
Одна из разновидностей электронной коммерции — контекстная Интернет-реклама. Сейчас на рынке таких услуг крупными игроками являются поисковые системы, немалую часть прибыли которых составляет так называемая поисковая реклама. Для России репрезентативными примерами служат рекламные Интернет-сервисы "Яндекс.Директ" и "Бегун".
Пользователю предлагается реклама, релевантная (с точки зрения поисковой системы) его поисковому запросу. В этом разделе мы не будем рассматривать задачу предоставления пользователю наиболее интересной ему поисковой рекламы. Наша задача — выявление рекламных слов, которые могут быть интересны рекламодателю.
Предположим, что некая фирма F приобрела ряд рекламных слов, которые описывают предоставляемые услуги. Как правило, на рынке уже существуют компании-конкуренты, поэтому вполне разумно было бы выяснить, какие рекламные слова приобрели они. Далее можно сравнить эти множества слов с теми, что купила F и, исходя из частоты таких покупок, отобрать наиболее интересные слова для нее из числа неприобретенных. Такой механизм стимулирует продажи рекламы и позволяет устраивать своеобразный аукцион по определению цены того или иного рекламного словосочетания.
Решение подобной задачи методами спектральной кластеризации описано в [88]. Цель наших экспериментов — не только расширить список методов бикластеризации, пригодных для решения этой задачи, но и улучшить качество предложенных рекомендаций. Ниже приведено описание исходного набора данных, постановка задачи, предложены методы для ее решения, описаны проведенные эксперименты и полученные результаты.
Постановка задачи и исходные данные
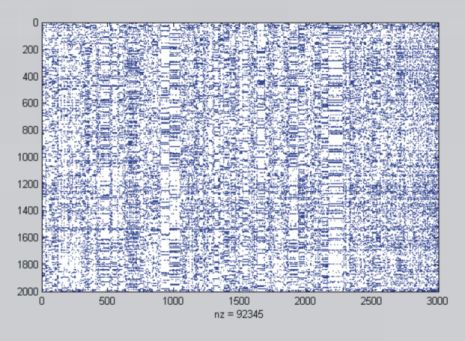
Данные для экспериментов принадлежат компании US Overture (ныне часть Yahoo) и описаны в работе [88]. Фактически, данные представляют собой двумерный массив, в котором строкам соответствуют фирмы (advertisers), а столбцам — рекламные слова (bids). Число фирм — 2000, а число рекламных словосочетаний — 3000. Число ненулевых ячеек 92345, соответственно, мера разреженности равна
![]() . Единица в ячейке означает, что фирма, соответствующая индексу строки, приобрела словосочетание, которое соответствует столбцу. Ноль означает отсутствие такой покупки.
. Единица в ячейке означает, что фирма, соответствующая индексу строки, приобрела словосочетание, которое соответствует столбцу. Ноль означает отсутствие такой покупки.
{kind=link}
Минимальное число заполненных ячеек в строке — 13. Это означает, что фирмы, представленные в наборе данных, покупают минимум 13 рекламных слов. Максимальное число заполненных ячеек в строке — 947. Минимальное число заполненных ячеек в столбце — 18, т.е. одно словосочетание покупает не меньше 18 фирм. Максимальное число непустых ячеек в столбце — 159.
По этим данным требуется построить бикластеры (фирмы, рекламные слова), которые представляют собой сегменты рынка. Далее такие бикластеры можно использовать для создания рекомендаций для фирм, действующих на этом же рынке, но не совершившим покупки слов, входящих в такой бикластер. В случае бикластеризации, допускающей незаполненные ячейки внутри бикластера, рекламные слова, отвечающие таким ячейкам, можно рассматривать в качестве кандидатов для рекомендаций.
Подобные рекомендации можно представлять в виде правил: "если фирма приобрела рекламное словосочетание A, то имеет смысл предложить ей словосочетание B". Такие правила "если-то" хорошо вписываются в парадигму поиска ассоциаций. В существующей научной литературе неоднократно описывались рекомендательные системы, основанные на анализе ассоциативных правил, см. [12]. Эти методы наряду с другими, используемыми в рекомендательных системах, показывают приемлемые результаты. Ниже мы опишем, как можно использовать семантическую и морфологическую информацию, заложенную в описании признаков (рекламных слов), и, тем самым, улучшить качество рекомендационных правил.
Вычислительная модель
Исходный массив данных описывается формальным контекстом
![]() ,
, ![]() (от firms) — множество компаний-рекламодателей, а
(от firms) — множество компаний-рекламодателей, а ![]() (от term) — множество рекламных словосочетаний,
(от term) — множество рекламных словосочетаний, ![]() — отношение инцидентности, показывающее, что фирма
— отношение инцидентности, показывающее, что фирма ![]() купила словосочетание
купила словосочетание ![]() тогда и только тогда, когда
тогда и только тогда, когда ![]() .
.
Для решения задачи мы последовательно применяли следущие подходы и алгоритмы:
- алгоритм D-miner для выявления крупных рынков средствами ФАП;
- поиск ассоциативных правил для построения рекомендаций;
- построение ассоциативных метаправил с помощью морфологического анализа;
- построение ассоциативных метаправил с помощью онтологий (тематического каталога);
1) Алгоритм D-miner — выявление крупных рынков средствами ФАП. Алгоритм D-miner подробно описан в работах [18] и [17]. Основное предназначение алгоритма — построение множества понятий по заданному контексту при ограничениях на размер объема и содержания. Фактически, задавая ограничение на размер объема понятия, мы строим так называемую решетку-айсберг. Аналогично при ограничении на размер содержания, мы строим "нижний" айсберг (т.е. нижнюю часть решетки).
Алгоритм D-miner принимает на вход контекст и два параметра — минимальные размеры объема понятия и содержания. При отличных от нуля ограничениях на размеры понятия на выходе алгоритма мы получим частично упорядоченное множество, представляющее "полосу" из средней части решетки, либо результат алгоритма будет пуст, если нет понятий, удовлетворяющих условиям отбора. Отметим, что алгоритм имеет приемлемую вычислительную сложность —
![]() ,
а его исполнимый файл доступен на сайте авторов.
,
а его исполнимый файл доступен на сайте авторов.
| Минимальный размер | Минимальный | Число |
| объема понятия | размер содержания | формальных понятий |
| 0 | 0 | 8 950 740 |
| 10 | 10 | 3 030 335 |
| 15 | 10 | 759 963 |
| 15 | 15 | 150 983 |
| 15 | 20 | 14 226 |
| 20 | 15 | 661 |
| 20 | 20 | 0 |
| 20 | 16 | 53 |
{kind=link}
Приведем примеры содержания формальных понятий для случая ![]() .
.
Рынок услуг по размещению сайтов
![]() affordable hosting web, business hosting web, cheap hosting, cheap hosting site web, cheap hosting web, company hosting web, cost hosting low web, discount hosting web, domain hosting, hosting internet, hosting page web, hosting service, hosting services web, hosting site web, hosting web
affordable hosting web, business hosting web, cheap hosting, cheap hosting site web, cheap hosting web, company hosting web, cost hosting low web, discount hosting web, domain hosting, hosting internet, hosting page web, hosting service, hosting services web, hosting site web, hosting web![]()
Рынок азартных игр.
![]() black casino jack, black gambling jack, black jack online, casino gambling, casino gambling online, casino game online, casino internet, casino line, casino net, casino online, casino roulette, casino slot, craps online, gambling internet, gambling online
black casino jack, black gambling jack, black jack online, casino gambling, casino gambling online, casino game online, casino internet, casino line, casino net, casino online, casino roulette, casino slot, craps online, gambling internet, gambling online ![]()
Гостиничный бизнес.
![]() angeles hotel los, atlanta hotel, baltimore hotel, dallas hotel, denver hotel, diego hotel san, francisco hotel san, hotel houston, hotel miami, hotel new orleans, hotel new york, hotel orlando, hotel philadelphia, hotel seattle, hotel vancouver
angeles hotel los, atlanta hotel, baltimore hotel, dallas hotel, denver hotel, diego hotel san, francisco hotel san, hotel houston, hotel miami, hotel new orleans, hotel new york, hotel orlando, hotel philadelphia, hotel seattle, hotel vancouver ![]()
2) Рекомендации на основе ассоциативных правил. По данному контексту построим с помощью программы Coron (см. раздел 3.3) информативный базис ассоциативных правил [75]. Информативный базис выбран нами, во-первых, для более компактного представления множества правил, а во-вторых, для повышения вычислительной эффективности. Напомним, что идея базиса состоит в том, что все остальные ассоциативные правила выводимы из него с помощью аксиом Армстронга. Результаты работы алгоритма приведены в таблице 5.2.
|
|
|
|
|
число правил |
| 30 | 86 | 0,9 | 1 | 101 391 |
| 30 | 109 | 0,8 | 1 | 144 043 |
Приведем также некоторые примеры построенных правил.
minsupp=30, minconf=0,9
-
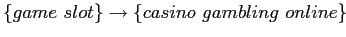 , supp=30 [1.50%]; conf=0.909 [90.91%];
, supp=30 [1.50%]; conf=0.909 [90.91%];
-
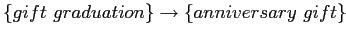 , supp=41 [2.05%]; conf=0.820 [82.00%];
, supp=41 [2.05%]; conf=0.820 [82.00%];
Величина поддержки ![]() для первого правила означает, что словосочетания "game slot" и "casino gambling online" купили 30 фирм. Величина достоверности
для первого правила означает, что словосочетания "game slot" и "casino gambling online" купили 30 фирм. Величина достоверности
![]() означает, что 90,9% фирм, которые покупают словосочетание "game slot", также покупают и "casino gambling online".
означает, что 90,9% фирм, которые покупают словосочетание "game slot", также покупают и "casino gambling online".
Далее для формирования рекомендаций для каждой конкретной фирмы можно применять подход, предложенный в [12]. Для покупателя слов ![]() находим все ассоциативные правила, в левой части которых содержатся им купленные слова. Далее строим множество
находим все ассоциативные правила, в левой части которых содержатся им купленные слова. Далее строим множество ![]() — уникальных рекламных словосочетаний, не купленных
— уникальных рекламных словосочетаний, не купленных ![]() ранее. Затем упорядочиваем найденные словосочетания по убыванию величины достоверности правил, в правую часть которых они входят. Если покупка одного и того же словосочетания предсказана несколькими правилами, то мы рассматриваем ассоциацию с наибольшей достоверностью.
ранее. Затем упорядочиваем найденные словосочетания по убыванию величины достоверности правил, в правую часть которых они входят. Если покупка одного и того же словосочетания предсказана несколькими правилами, то мы рассматриваем ассоциацию с наибольшей достоверностью.
3) Построение метаправил на основе морфологии рекламных слов признакового пространства. Рассмотрим в качестве дополнительного знания имеющееся признаковое пространство, а именно, тот факт, что каждый признак является словом или словосочетанием. Вполне очевидно, что синонимичные словосочетания принадлежат к одному сегменту рынка. Конечно, в штате компаний, занимающихся контекстной рекламой, существуют тематические каталоги, составленные экспертами, но ввиду большого количества рекламных слов (несколько тысяч) наполнение каталога "вручную" является сложной задачей.
Для построения тематического каталога рекламных словосочетаний могут потребоваться словари синонимов, а из-за того, что такие словосочетания не всегда являются словами или сочетаниями двух слов, такие словари редки. К тому же, рекламное словосочетание может включать специфические сокращения, отсутствующие в словарях синонимов общего назначения. Поэтому в качестве первого приближения для решения такой задачи можно использовать стемминг, или выделение основы слова. Опишем последовательность действий при извлечении знаний с помощью стемминга.
Пусть ![]() — некое рекламное словосочетание. Представим это словосочетание в виде множества образующих его слов
— некое рекламное словосочетание. Представим это словосочетание в виде множества образующих его слов
![]() .
Основу слова
.
Основу слова ![]() обозначим через
обозначим через
![]() . Множество основ словосочетания
. Множество основ словосочетания ![]() обозначим через
обозначим через
![]() .
Построим формальный контекст
.
Построим формальный контекст
![]() ,
где
,
где ![]() — множество всех словосочетаний, а
— множество всех словосочетаний, а ![]() — множество основ всех словосочетаний из
— множество основ всех словосочетаний из ![]() ,
т.е.
,
т.е.
![]() .
Тогда
.
Тогда ![]() будет означать, что во множество основ словосочетания
будет означать, что во множество основ словосочетания ![]() входит основа
входит основа ![]() .
.
Построим по такому контексту правила вида
![]() для всех
для всех ![]() .
Тогда такому метаправилу контекста
.
Тогда такому метаправилу контекста
![]() соответствует
соответствует
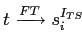 — ассоциативное правило контекста
— ассоциативное правило контекста
![]() .
Если величина поддержки и достоверности такого правила в контексте
.
Если величина поддержки и достоверности такого правила в контексте
![]() превышают некоторые пороговые значения, то можно считать ассоциативные правила, построенные по контексту
превышают некоторые пороговые значения, то можно считать ассоциативные правила, построенные по контексту
![]() ,
не столь интересными (их можно вывести из описания признаков).
,
не столь интересными (их можно вывести из описания признаков).
В качестве более крупных метаправил мы предлагаем следующие две возможности. Во-первых, можно искать правила вида
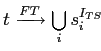 ,
т.е. правила, в правую часть которых входят все термы, имеющие хотя бы одно однокоренное слово с исходным термом. Во-вторых, правила вида
,
т.е. правила, в правую часть которых входят все термы, имеющие хотя бы одно однокоренное слово с исходным термом. Во-вторых, правила вида
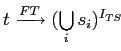 ,
т.е. правила, термы в правой части которых содержат те же основы, что и исходный терм. Довольно очевидно, что первый тип правил может привести к объединению различных словосочетаний, например "black jack" — игровой бизнес и "black coat" — одежда. Такое объединение произошло благодаря наличию общего слова "black". Второй тип правил относится к более редким зависимостям, например,
,
т.е. правила, термы в правой части которых содержат те же основы, что и исходный терм. Довольно очевидно, что первый тип правил может привести к объединению различных словосочетаний, например "black jack" — игровой бизнес и "black coat" — одежда. Такое объединение произошло благодаря наличию общего слова "black". Второй тип правил относится к более редким зависимостям, например,
![]() .
Поэтому меры поддержки и достоверности при построении простых метаправил должны служить их мерой пригодности для дальнейшего использования.
.
Поэтому меры поддержки и достоверности при построении простых метаправил должны служить их мерой пригодности для дальнейшего использования.
Мы предлагаем также использовать метаправила вида
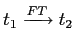 ,
такие что
,
такие что
![]() .
Такие правила имеют простую интерпретацию: из словосочетания
.
Такие правила имеют простую интерпретацию: из словосочетания ![]() следует словосочетание, множество основ которого вкладывается в множество основ
следует словосочетание, множество основ которого вкладывается в множество основ ![]() .
.
Примеры метаправил.
-
;
-
;
-
{mail order phentermine} → {adipex online order, adipex order,adipex phentermine,
phentermine prescription, phentermine purchase, phentermine sale},
Supp = 19; Conf = 0,95; -
;
-
{distance long phone} → {call distance long phone, carrier distance long phone,
distance long phone rate, distance long phone service},
Supp = 37, Conf = 0,88; -
,
такие что
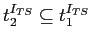 ;
;
-
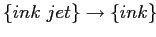 ,
Supp = 14; Conf = 0,7.
,
Supp = 14; Conf = 0,7.
4) Построение онтологии и семантических метаправил на ее основе. Несмотря на то, что в информатике не существует общего формального определения понятия онтологии, можно выделить его основные черты: понятия, иерархическое отношение IS-A и другие отношения. Мы будем следовать определению, приведенному в [72]:
Онтология — это кортеж
![]() ,
где
,
где ![]() — множество, элементы которого называются понятиями,
— множество, элементы которого называются понятиями, ![]() — частичный порядок на
— частичный порядок на ![]() ,
,
![]() — множество, элементы которого называются именами отношений (или просто отношениями) и
— множество, элементы которого называются именами отношений (или просто отношениями) и
![]() — функция, которая сопоставляет каждому отношению его арность.
— функция, которая сопоставляет каждому отношению его арность.
В нашем случае множество понятий — все рекламные слова, упорядоченные отношением быть "более общим понятием". Например, в нашей онтологии для рынка лекарств и медицинских средств понятие "медицинские препараты" — более общее, чем "витамины".
В нашем случае будем использовать упрощенную "древесную" онтологию. Введем два оператора, действующих на множестве рекламных слов ![]() :
оператор уровня обобщения
:
оператор уровня обобщения
![]() ,
значения которого образуют более общие понятия на
,
значения которого образуют более общие понятия на ![]() уровней выше, и оператор соседства
уровней выше, и оператор соседства
![]() ,
множество значений которого состоит из понятий одного уровня и общим родителем с данным понятием.
,
множество значений которого состоит из понятий одного уровня и общим родителем с данным понятием.
Теперь определим два вида метаправил для онтологии: правила общности
![]() и правила соседства
и правила соседства
![]() .
Такие правила также будем рассматривать, как ассоциации контекста
.
Такие правила также будем рассматривать, как ассоциации контекста
![]() ,
что позволит понять, какие из них подтверждаются имеющимися данными.
,
что позволит понять, какие из них подтверждаются имеющимися данными.
Примеры метаправил для рынка медикаментов.
Правило вида
![]() ,
где
,
где
![]() :
:
{B_VITAMIN} → {B_COMPLEX_VITAMIN, B12_VITAMIN, C_VITAMIN, D_VITAMIN,
DISCOUNT_VITAMIN, E_VITAMIN, HERB_VITAMIN, MINERAL_VITAMIN,
MULTI_VITAMIN, SUPPLEMENT_VITAMIN, VITAMIN}
Правило вида
![]() ,
где
,
где
![]() :
:
![]() .
.
Верификация результатов
Для проверки результатов, полученных нами с помощью поиска ассоциативных правил, мы применяем скользящий контроль (cross validation). Для это мы разбиваем исходную выборку случайным образом на 10 частей, далее последовательно используем одну часть в качестве контрольной выборки (test set), а остальные 9 рассматриваем как единую обучающую выборку(training set). При этом ассоциативные правила, полученные нами по обучающей выборке, будем записывать в виде
![]() .
.
Тогда мерой качества такого ассоциативного правила при проверке на контрольной выборке будет служить величина
![]() .
Значение этой величины показывает долю фирм, покупающих множества словосочетаний A и B, из тех фирм, которые приобретали только множество словосочетаний A. Как видим, это не что иное, как определение поддержки ассоциативного правила на контрольной выборке:
.
Значение этой величины показывает долю фирм, покупающих множества словосочетаний A и B, из тех фирм, которые приобретали только множество словосочетаний A. Как видим, это не что иное, как определение поддержки ассоциативного правила на контрольной выборке:
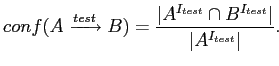
Мы построили 10 множеств ассоциативных правил для 10-ти различных выборок по 1800 фирм каждая и вычислили величину достоверности таких правил на контрольной выборке, содержащей 200 объектов. Ассоциативные правила мы искали для значений минимальной поддержки 27 (
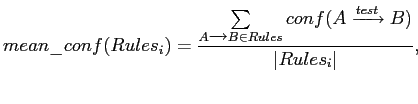
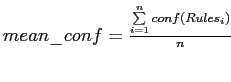 .
.
| Число | Число | mean_conf | Число правил | mean_conf | |
| правил | подтвержденных правил | min_conf=50% | (min_conf=50%) | ||
| 1 | 147170 | 73025 | 0,77 | 65556 | 0,84 |
| 2 | 69028 | 68709 | 0,93 | 68495 | 0,93 |
| 3 | 89332 | 89245 | 0,95 | 88952 | 0,95 |
| 4 | 107036 | 93078 | 0,84 | 86144 | 0,90 |
| 5 | 152455 | 126275 | 0,82 | 113008 | 0,90 |
| 6 | 117174 | 114314 | 0,89 | 111739 | 0,91 |
| 7 | 131590 | 129826 | 0,95 | 128951 | 0,96 |
| 8 | 134728 | 120987 | 0,96 | 106155 | 0,97 |
| 9 | 101346 | 67873 | 0,72 | 52715 | 0,92 |
| 10 | 108994 | 107790 | 0,93 | 106155 | 0,94 |
| means | 115885 | 99112 | 0,87 | 92787 | 0,92 |
Усредненная достоверность правил на контрольной выборке не сильно снижается по сравнению с минимальной достоверностью для обучающей выборки, т.е.
![]() .
.
В качестве средства валидации для метаправил мы используем меру достоверности. Величина поддержки не играет большой роли, так как мы ищем не столько крупные рынки или наиболее продаваемые словосочетания, сколько устойчивые закономерности при покупке. Правила с достоверностью меньше 0.5 нас не так сильно интересуют, потому что они означают, что в половине случаев покупка может произойти, а в половине — нет (своеобразная игра в подбрасывание монеты).
Для ассоциативных правил мы изначально задались высоким уровнем достоверности — 0.8 и 0.9. Для метаправил значения поддержки и достоверности необходимо вычислить по контексту
![]() . Приведем значения этих мер в сводных таблицах для метаправил, построенных с использованием морфологии. Также в таблице указано число правил, имеющих поддержку отличную от 0.
. Приведем значения этих мер в сводных таблицах для метаправил, построенных с использованием морфологии. Также в таблице указано число правил, имеющих поддержку отличную от 0.
| Тип правила | Среднее значение supp | Среднее значение conf | Число правил |
|
|
6 | 0,26 | 2389 |
|
|
6 | 0,24 | 456 |
|
|
12 | 0,40 | 1095 |
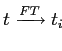 ,
такие что ,
такие что
|
15 | 0,49 | 7409 |
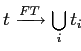 ,
такие что ,
такие что
|
11 | 0,36 | 2006 |
Зададим уровень минимальной поддержки 0,5 и установим число правил каждой группы, для которых превышен этот порог.
| Тип правила | Среднее значение supp | Среднее значение conf | Число правил |
|
|
15 | 0,64 | 454 |
|
|
15 | 0,63 | 75 |
|
|
18 | 0,67 | 393 |
|
, такие что
|
21 | 0,70 | 3922 |
|
, такие что
|
20 | 0,69 | 673 |
По таблицам 5.4 и 5.5 легко установить что наиболее достоверными и часто встречающимися являются правила вида
.
Отметим, что использование морфологии является полностью автоматическим приемом, позволяющим найти ассоциации заранее. Остается также часть правил, не подтвержденная значениями поддержки и достоверности. Можно провести ее верификацию для более репрезентативных данных, например, на множестве словосочетаний, которые рекомендуются службой Google AdWords, учитывающей частоту запросов по словам-синонимам для многомиллионной аудитории пользователей.
Наиболее достоверные правила может дать онтология (в данной задаче — заранее составленный экспертами каталог).
Выводы и дальнейшие исследования
Полученные результаты показывают, что часть зависимостей в базе данных покупок рекламных слов можно выявлять автоматически, не прибегая к трудоемким методам, а используя стандартные методы компьютерной лингвистики. Предложенные подходы вкупе с с методами Data Mining помогают улучшить рекомендации и обеспечивают хорошее средство частотного ранжирования, что удобно при составлении Top-N рекомендаций. Еще одно преимущество подхода состоит в возможности выявить связанные рекламные слова, не используемые по каким-то причинам рекламодателями. Результаты бикластеризации на основе ФАП показывают возможность выявления относительно крупных рекламных рынков (более 20-ти участников), описанных в терминах фирм-участников и рекламных слов.
В качестве дальнейших исследовательских задач отметим следующие:
- проверка предложенного подхода на больших массивах реальных данных с применением методов скользящего контроля (разбиение исходного массива на обучающую и тестовую выборку);
- использование готовых онтологий типа WordNet для построения метаправил.