SQL/MapReduce: практический подход к поддержке самоописываемых, полиморфных и параллелизуемых функций, определяемых пользователями
Эрик Фридман, Питер Павловски и Джон Кислевич
Перевод: Сергей Кузнецов
3. Синтаксис и функциональные возможности
В этом разделе мы представляем синтаксис вызовов SQL/MR-функций из стандартных запросов SQL (подраздел 3.1), модель выполнения, обеспечиваемую SQL/MR-функциями (подраздел 3.2) и API для реализации SQL/MR-функций (подраздел 3.3). Мы также обсуждаем инсталляцию SQL/MR-функций (подраздел 3.4) и использование других файлов в ходе выполнения SQL/MR (подраздел 3.5).
3.1 Синтаксис запросов
Синтаксис использования SQL/MR-функций показан на рис. 4. Вызов SQL/MR-функции может использоваться в разделе FROM SQL-запроса и состоит из имени функции, за которым следует заключенный в круглые скобки список разделов. Первым, единственным необходимым разделом является раздел ON, специфицирующий входные данные для этого вызова SQL/MR-функции. Раздел ON должен содержать некоторый допустимый запрос. Допускается и ссылка на таблицу, но в действительности это следует считать всего лишь синтаксическим упрощением для представления запроса, выбирающего все строки и столбцы из указанной таблицы. Если используется запрос, то он должен быть заключен в круглые скобки, подобно тому, как и подзапрос, используемый в разделе FROM, должен заключаться в круглые скобки. Важно заметить, что входная схема SQL/MR-функции специфицируется неявным образом во время формирования плана выполнения запроса как схема результата запроса, используемого в разделе ON.

Рис. 4. Синтаксис запроса с вызовом SQL/MR-функции.
3.1.1 Разделение
Следующим разделом вызова SQL/MR-функции является PARTITION BY, содержащий разделенный запятыми список выражений, используемых для разделения входной таблицы SQL/MR-функции. Эти выражения могут содержать ссылки на любые атрибуты из схемы запроса или ссылки на таблицу из раздела ON. В подразделе 3.3 роль раздела PARTITION BY будет описана значительно подробнее.
3.1.2 Сортировка
За разделом PARTITION BY следует раздел ORDER BY, в котором указывается порядок сортировки входных данных SQL/MR-функции. Раздел ORDER BY может использоваться в вызове SQL/MR-функции, только если в нем используется и раздел PARTITION BY. В разделе ORDER BY могут использоваться ссылки на любые атрибуты из схемы запроса или ссылки на таблицу из раздела ON, и в нем указывается разделенный запятыми список выражений, допустимых в разделе ORDER BY стандартного SQL.
3.1.3 Разделы специальных архумеентов
Вслед за разделом ORDER BY пользователь может добавить произвольное число разделов специальных аргументов. Раздел специального аргумента содержит имя раздела, за которым следует разделенный запятыми список литерально задаваемых аргументов. SQL/MR-функция при своей инициализации получит таблицу "ключ-значение" с именами этих разделов м значениями аргументов. Использование разделов специальных аргументов позволяет индивидуализировать функциональные возможности SQL/MR-функций во время выполнения запросов и является одним из способов обеспечения динамического полиморфизма.
3.1.4 Использование как отношения
Результатом вызова SQL/MR-функции является некоторое отношение; следовательно этот результат может использоваться в разделе FROM запроса точно так же, как и любая допустимая ссылка на таблицу или любой допустимый подзапрос. Вызов SQL/MR-функции не обязан быть единственным выражением в разделе FROM. Например, результаты двух вызовов SQL/MR-функций можно соединить один с другим или с некоторыми таблицей либо подзапросом. Кроме того, поскольку результатом вызова SQL/MR-функции является таблица, и при вызове SQL/MR-функции входные данные поставляются в виде таблицы, вызовы SQL/MR-функций могут вкладываться, как это показано на рис. 5.
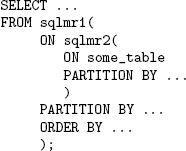
Рис. 5. Вложенность вызовов SQL/MR-функций.
3.2 Модель выполнения
Модель выполнения, обеспечиваемая SQL/MR-функциями, является обобщением модели MapReduce [7]. Если использовать термины MapReduce, SQL/MR-функция может быть либо отображателем (mapper), либо сжимателем (reducer), что мы назывем функцией над строками (row function) и функцией над разделами (partition function) соответственно. В SQL/MR-функциях можно реализовать оба интерфейса, если для данной функции осмысленны оба режима работы. Как показано на рис. 5, по причине интеграции SQL/MR с SQL тривиально образуется любая комбинация map и reduce SQL/MR-функций. В SQL/MR допускается любое число и любой порядок вызовов функций map и reduce, вставленных в SQL-запрос, в то время как в MapReduce можно вызвать только одну функцию map, а затем только одну функцию reduce.
Модель выполнения SQL/MR разработана для использования в массивно-параллельной СУБД и поэтому должна быть по умолчанию параллельной. Экземпляры функции SQL/MR будут выполняться параллельно в каждом узле параллельной СУБД, точно так же, как в среде MapReduce в кластере выполняются задачи map и reduce. Число экземпляров SQL/MR-функции в одном рабочем узле не фиксированно. Каждый экземпляр видит некоторый уникальный набор строк, т.е. каждая строка обрабатывается только одним экземпляром SQL/MR-функции. Определения функций над строками и разделами обеспечивают их параллельное выполнение масштабируемым образом. Даже при наличии в СУБД всего одного узла инфраструктура SQL/MR остается полезной, поскольку обеспечивает полиморфные и самоописываемые UDF, которые могут распараллеливаться на нескольких процессорных ядрах.
Теперь мы опишем функции над строками и разделами, а также покажем, как их модели выполнения поддерживают параллелизм.
- Функция над строками. Каждая строка входной таблицы будет обрабатыватьтся ровно одним экземпляром SQL/MR-функции. Как описывается в разд. 4, с точки зрения семантики каждая строка обрабатывается независимо, что позволяет механизму поддержки выполнения контролировать параллелизм. Для каждой входной строки каждая функция над строками может произвести ноль или большее число строк. Функции над строками похожи на функцию map среды MapReduce; основной смысл функций над строками состоит в выполнении низкоуровневых преобразований и обработки.
- Функция над разделами. Каждая группа строк, определяемая в соответствии с разделом
PARTITION BY, будет обрабатываться в точности одним экземпляром SQL/MR-функции, и этот экземпляр функции получит сразу всю группу строк. Если в вызове функции присутствовал и разделORDER BY, строки внутри каждого раздела поступают в экземпляр функции уже должным образом упорядоченными. С точки зрения семантики каждый раздел обрабатывается независимо, что позволяет механизму поддержки выполнения производить распараллеливание на уровне разделов. Для каждого входного раздела SQL/MR-функция над разделами может производить ноль или большее число строк. Функции над разделами похожи на функцию reduce в MapReduce. Мы называем их функциями над разделами, чтобы подчеркнуть их использование в групповой обработке, поскольку в важных сценариях использования такая функция в действительности не сокращает размер набора данных.
3.3 Интерфейс программирования
В этом подразделе мы опишем интерфейс программирования. На рис. 6 показан Java-класс, реализующий SQL/MR-функцию sessionize (для нашего сквозного примера формирования пользовательских сессий).
public class Sessionize implements PartitionFunction
{
// Constructor (called at initialization)
public Sessionize (RuntimeContract contract)
{
InputInfo inputInfo = contract.get InputInfo() ;
// Determine time column
String timeColumnName =
contract.useArgumentClause(”timecolumn”).getSingleValue();
timeColumnIndex_ = inputInfo.getColumnIndex(timeColumnName);
// Determine timeout
String timeoutValue =
contract.useArgumentClause(”timeout”).getSingleValue();
timeout_ = Integer.parseInt(timeoutValue);
// Define output columns
List outputColumns =
new ArrayList();
outputColumns.addAll(inputInfo.getColumns());
outputColumns.add(new ColumnDefinition(”sessionid”, SqlType.integer()));
// Complete the contract
contract.setOutputInfo( new OutputInfo(outputColumns));
contract.complete();
}
// Operate method ( called at runtime, for each partition)
public void operateOnPartition(
PartitionDefinition partition,
RowIterator inputIterator, // Iterates over all rows in the partition
RowEmitter outputEmitter // Used to emit output rows
)
{
int currentSessionId = 0 ;
int lastTime = Integer.MIN_VALUE;
// Advance through each row in partition
while (inputIterator.advanceToNextRow())
{
// Determine if time of this click is more than timeout after the last
int currentTime = inputIterator.getIntAt(timeColumnIndex_);
if(currentTime > lastTime + timeout_)
++currentSessionId;
// Emit ouput row with all input columns, plus current session id
outputEmitter.addFromRow(inputIterator);
outputEmitter.addInt(currentSessionId);
outputEmitter.emitRow();
lastTime = currentTime;
}
}
// State saved at initialization, used during runtime
private int timeColumnIndex_;
private int timeout_;
};
Рис. 6. Реализация повторно используемой функции sessionize с использованием Java API SQL/MR.
3.3.1 Контракт времени выполнения
Для обеспечения самоописания SQL/MR-функций мы выбрали метафору контракта. Во время подготовки плана выполнения запроса оптимизатор запросов nCluster заполняет некоторые поля объекта контракт времени выполнения, такие как имена и типы столбцов входной таблицы, имена и значения разделов аргументов. Эта неполная информация затем во время подготовки плана передается подпрограмме инициализации SQL/MR-функции.
Конструктор должен завершить контракт, заполнив дополнительные поля, такие как схема результата, и затем вызвать метод complete(). От всех экземпляров SQL/MR функции требуется соблюдение этого контракта, так что в заполнении контракта должны участвовать только детерминированные входные данные.
При использовании традиционных UDF также имеется некоторая разновидность контракта: при инсталляции функции должны быть явно объявлены типы ее параметров и возвращаемого значения (в операции CREATE FUNCTION). Это делается конечным пользователем или администратором базы данных. В отличие от этого, SQL/MR функции не только являются самоописываемыми, но согласование контракта во время подготовки плана запроса позволяет функции динамически изменять свою схему, что добавляет существенную гибкость, позволяющую создавать функции, пригодные для повторного применения. Большее число примеров будет приведено в разд. 5.
Справочная информация. Поскольку согласование контракта и, следовательно, определение схемы результата происходит во время подготовки плана выполнения запроса, полезно предоставить создателю запроса средства обнаружения схемы результата вызова интересующей его SQL/MR-функции. Это обеспечивается за счет использования самоописываемой природы SQL/MR-функций, а также описанного выше свойства детерминированности согласования контракта. Подобно тому, как во многих инструментах командной строки имеется опция "help", разработчики SQL/MR-функций снабжаются справочной информацией через соответствующий API. Обеспечивается информация об обязательных и необязательных разделах аргумеентов, а также о схеме результата при заданной схеме входной таблицы.
Валидация разделов аргументов. SQL/MR автоматически гарантирует, что в запросе определяются разделы аргументов вызова функции, совместимые с ее реализацией: если некоторый раздел аргументов присутствует в вызове, но не используется в реализации, или если функция пытается обращаться к разделу аргументов, отсутствующему в вызове, то пользователю направляется сообщение об ошибке. Например, оба раздела аргументов, заданные в запросе с рис. 3, используются конструктором Sessionize на рис. 6. Чтобы допустить наличие необязательных разделов аргументов, контруктор функции SQL/MR может проверять наличие конкретных разделов аргументов.
3.3.2 Функции для обработки данных
Наиболее важными в API являются методы OperateOnSomeRows и OperateOnPartition, которые являются частями интерфейсов функций над строками и разделами соответственно. Эти методы составляют механизм вызова SQL/MR-функции. Функции предоставляется итератор над строками, для обработки которых она вызвана, а также объект "emitter" для возврата строк в базу данных. Метод OperateOnPartition также включает объект PartitionDefinition, который обеспечивает значения выражений PARTITION BY. Это полезно, поскольку столбцы, используемые для вычисления этих значений, могут не входить в число входных данных функции.
На рис. 6 показана реализация функции OperateOnPartition для SQL/MR-функции Sessionize. Каждая результирующая строка конструируется из одной входной строки и текущего значения идентификатора сессии. Заметим, что результирующие атрибуты добавляются к источнику выходных данных в порядке слева направо.
3.3.3 Функции-комбинаторы
Одна из оптимизаций в реализации MapReduce компании Google [7] состоит в поддержке функций-комбинаторов. Функции-комбинаторы уменьшают объем данных, которые требуется передавать по сети, путем комбинирования (вычисления агрегатов) строк в локальных разделах. Использование комбинатора является чистой оптимизацией; это не влияет на окончательный результат вычислений.
В SQL/MR комбинирование поддерживается как опция при реализации функции над разделами. В некоторых случаях требуется передача данных по сети для формирования входных разделов для функций над разделами. Если в функции над разделами реализуется необязательный интерфейс для комбинирования, оптимизатор запросов при построении плана запроса может принять решение воспользоваться возможностью комбинирования до передачи данных по сети, сокращая число строк, которые придется передавать.
Мы осознанно из-за особенностей использования представляем средство комбинирование как деталь функции над разделами, а не как специальную разновидность функции. С точки зрения пользователя, составляющего запрос с вызовом функции над разделами, выполнение комбинирование не вносит какого-либо изменения в семантику. По этой причине мы оставили комбинирование деталью реализации, которая может приниматься во внимание разработчиком SQL/MR-функции, но является прозрачной для пользователей функции.
3.3.4 Скользящие агрегаты
В SQL/MR имеется механизм для вычисления в SQL/MR-функции скользящих SQL-агрегатов над данными. Это позволяет функции обеспечивать для своих пользователей полный набор знакомых SQL-агрегатов с минимальными усилиями. Функция может запросить новый скользящий агрегат по имени и типу (например, avg(numeric)), изменять этот агрегат с использованием новых значений, запрашивать текущее значение агрегата и сбрасывать значение агрегата. Динамически можно запрашивать агрегаты над данными любого типа, что полезно для полиморфных функций, которые невозможно разрабатывать в расчете на конкретные типы данных. Кроме того, эти агрегаты соответствуют семантике SQL, которая для некоторых типов данных является достаточно изощренной.
3.4 Инсталляция SQL/MR-функции
Чтобы начать использовать некоторую SQL/MR-функцию, ее необходимо инсталлировать. Мы используем общее средство установки файлов (описываемое в подразделе 3.5) для загрузки и контролирования файла, содержащего выполняемый код. После установки файла система анализирует его содержимое, чтобы определить, является ли оно функцией. Поскольку функции являются самоописываемыми, не требуется какое-либо конфигурирование или выполнение оператора CREATE FUNCTION, и SQL/MR-функцию сразу после инсталляции можно использовать в запросах. При анализе файла во время инсталляции устанавливаются и другие статические свойства функции, например, является ли она функцией над строками или же функцией над разделами, поддерживает ли она комбинирование, какова ее справочная информация и т.д.
В действительности файлы функции могут содержаться в .zip-архиве, включающем файл функции и библиотеки сторонних поставщиков. Эти библиотеки делаются доступными для данной функции; например, в случае использования Java они автоматически включаются в ее путь к классам (classpath). Это полезно в самых разных целях: пакет линейной алгебры для решения линейных уравнений, библиотека обработки естественного языка и т.д.
3.5 Инсталлируемые файлы и временные каталоги
Для содействия распространению конфигурационных файлов и других вспомогательных файлов данных система позволяет пользователям инсталлировать произвольные файлы, а не только файлы функций. При установке файла он реплицируется на всех рабочих узлах, что обеспечивает возможность его чтения SQL/MR-функциями. Каждой функции также предоставляется некоторый временный каталог, который очищается после завершения выполнения функции, и использование которого отслеживается при выполнении функции.
Мы обнаружили, что эти возможности полезны для распространения конфигурационных файлов, статических файлов данных, содержащих, например, словари, а также для инсталляции бинарных файлов, которые затем могут выполняться в некоторой SQL/MR-функции. В последнем сценарии использования упор делается на удобство использования: в некоторых случаях оказывается возможным быстро поместить существующие C-программы в бинарной форме в среду параллельного выполнения без серьезных трудозатрат на преобразование этих программ в библиотеки со строго определеными API.