СУБД с хранением данных по столбцами и по строкам: насколько они отличаются в действительности?
Дэниэль Абади, Сэмюэль Мэдден, Набил Хачем
Пересказ: Сергей Кузнецов
6.2. Моделирование колоночного хранилища в строчном хранилище
В этом подразделе описывается производительность различных конфигураций System X на тестовом наборе Star Schema Benchmark. System X конфигурировалась таким образом, чтобы таблица LINEORDER разделялась на столбце orderdate по годам (это значит, что для каждой группы кортежей с одинаковым значением года принятия заказа создавался отдельный физический раздел). Как было сказано в подразделе 6.1, это разделение существенно ускоряет выполнение запросов из SSBM, включающих предикат на столбце LINEORDER (в запросах 1.1, 1.2, 1.3, 3.4, 4.2 и 4.3 требуются данные за период в пределах одного года, а в менее селективных запросах 3.1, 3.2 и 3.3 запрашиваются данные за период с 1992-го по 1997-й гг., т.е. за половину всего временого промежутка, зафиксированного в базе данных). К сожалению, дела обстоят не так хорошо для представлений данных, ориентированных на хранение данных по столбцам. System X не разрешает горизонтально разделять по orderdate двухколоночные вертикальные разделы (поскольку они не содержат столбца orderdate, за исключением, конечно, вертикального раздела orderdate). Это означает, что для тех звеньев запросов, которые ограничивают столбец orderdate, подходы, ориентированные на хранение данных по столбцам, находятся в менее выигрышном положении, чем базовый вариант.
Тем не менее, авторы решили использовать разделение для базового варианта, потому что хороший администратор баз данных непременно воспользовался бы этой стратегией для повышения производительности при выполнении этих запросов в строчном хранилище. При использовании базового варианта без разделения система демонстрировала производительность, меньшую в среднем в два раза (хотя это зависело от селективности предиката на столбце orderdate). Таким образом, авторы полагают, что разделение таблицы LINEORDER позволило бы повысить производительность в среднем в два раза, если бы было можно разделять таблицы на основе двух уровней косвенности (по первичному ключу, или идентификатору записи достается значение столбца orderdate, а через orderdate получается значение года).
К числу других уместных конфигурационных параметров System X относится следующее: размер дисковых страниц – 32 килобайта, максимальный размер оперативной памяти для выполнения сортировок, соединений и хранения промежуточных результатов – 1.5 гигабайт, размер буферного пула – 50 мегабайт. Авторы экспериментировали с другими размерами буферного пула и обнаружили, что изменение его размера не сильно влияет на время выполнения запросов (поскольку в этом тестовом наборе преобладает использование просмотров большой таблицы), если только не использовать совсем маленький буферный пул. Авторы включили режимы сжатия и упреждающего чтения при последовательном сканировании и обнаружили, что оба эти приема способствуют повышению производительности, опять же, из-за того, что при обработке запросов требуется большой объема ввода-вывода. В System X также поддерживается метод звездообразного соединения, и оптимизатор может использовать фильтры Блюма, если по его оценкам это может повысить производительность выполнения запроса.
Как говорилось в разд. 4, авторы при прогоне запросов SSBM проводили эксперименты с пятью конфигурациями System X:
- «традиционное» строчное представление; в System X разрешалось использование битовых индексов и фильтров Блюма, если это способствовало эффективности;
- «традиционный подход с использованием битовых индексов»; этот подход похож на первый, но в данном случае используются планы выполнения запросов, которые ориентированы на применение битовых индексов, что временами вынуждает оптимизатор производить планы, уступающие планам чисто традиционного подхода;
- подход с «вертикальным разделением», при котором каждому столбцу соответствует собственное отношение с идентификаторами записей из исходного отношения;
- представление на основе только индексов с использованием отдельного некластеризованного B-дерева на каждом столбце исходных таблиц базы данных и выполнение запросов путем чтения значений прямо с индексов;
- подход «материализованных представлений» с обеспечением для каждого запроса оптимального набора материализованных представлений (в этих запросах соединения заранее не выполняются).
Детальные результаты для каждого потока запросов показаны на рис. 6(a), а усредненные результаты для всех запросов – на рис. 6(b). Во всех случаях лучшую производительность демонстрирует подход с материализованными представлениями, поскольку в этом случае для обработки запроса требуется чтение минимального объема данных. Второе место по производительности занимает традиционный подход (или традиционный подход с использованием битовых индексов). В среднем традиционный подход работает почти в три раза быстрее наилучшего варианта эмуляции колоночного хранилища в строчном хранилище. Как уже говорилось выше, это особенно характерно для запросов, при выполнении которых используется разделение по orderdate. Для второго звена запросов (для выполнения которых разделение не обеспечивает преимуществ) подход с вертикальным разделением успешно конкурирует с традиционным подходом; подход с использованием только индексов работает плохо по причинам, объясняемым ниже. Прежде чем более детально обсудить эффективность выполнения отдельных запросов, авторы резюмируют две высокоуровневые проблемы, ограничивающие эффективность колоночного подхода: покортежные накладные расходы и неэффективная реконструкция кортежей.
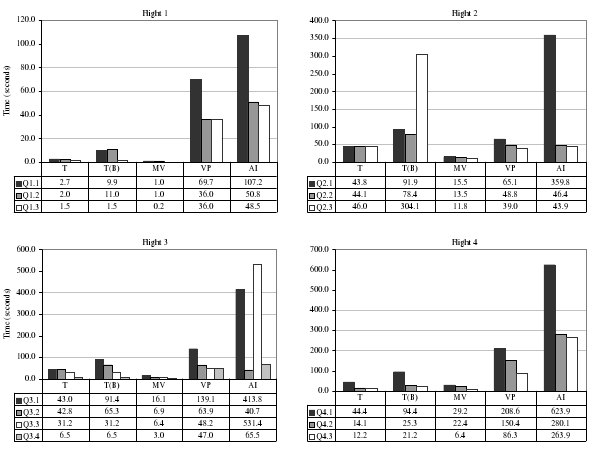
Рис. 6(a). Показатели производительности по звеньям запросов для различных вариантов конфигурирования строчного хранилища. Здесь T – соответствует традиционному варианту, T(B) – традиционному варианту с ориентацией на битовые индексы, MV – варианту с материализованными представлениями, VP – варианту с вертикальным разделением и AI – варианту с использованием только индексов.
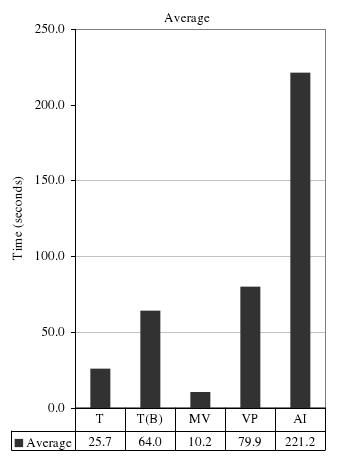
Рис. 6(b). Средняя производительность по всем запросам.
Покортежные накладные расходы. Как отмечалось в [16], одной из проблем подхода с полным вертикальным разделением в строчном хранилище является то, что могут стать довольно большими покортежные накладные расходы. Эту проблему отягчает тот факт, что для обеспечения реконструирования кортежей вместе с каждым столбцом требуется хранить идентификаторы записей или первичные ключи. Авторы сравнивали размеры колоночных таблиц, возникающих при применении подхода с вертикальным разделением, с размерами традиционных таблиц строчного хранилища и обнаружили, что для хранения одной колоночной таблицы для столбцов таблицы LINEORDER из базы данных SSBM с коэффициентом масштабирования 10 (около 60 миллионов кортежей) требуется от 0.7 до 1.1 гигабайт данных после сжатия – это означает, что для каждой строки требуется 8 байт в дополнение к 4 байтам для каждого идентификатора записи и каждого значения самого столбца (в зависимости от типа данных столбца и эффективности сжатия (16 байт × 6 × 107 кортежей = 960 мегабайт). По сравнению с этим, таблица LINEORDER целиком, со всеми семнадцатью столбцами при применении традиционного подхода занимает без сжатия около шести гигабайт, а в сжатом виде – 4 гигабайта. Тем самым, сканирование всего лишь четырех столбцов вертикально разделенной таблицы займет столько же времени, что сканирование всей таблицы фактов при использовании традиционного подхода. Для сравнения, в C-Store для хранения одного столбца целого типа требуется всего 240 мегабайт (4 байта × 6 × 107 кортежей = 240 мегабайт), а вся таблица в сжатом виде занимает 2.3 гигабайта.
Соединения столбцов. Как отмечалось выше, для слияния двух столбцов одной и той же таблицы требуется операция соединения. В System X для выполнения этих операций предпочитается использование хэш-соединений. Авторы проводили эксперименты по принуждению System X к использованию соединений с помощью индексных вложенных циклов и соединений со слиянием, но обнаружили, что это не способствует повышению производительности, поскольку доступ через индексы вызывает высокие накладные расходы, а при выполнении соединения со слиянием System X не может обойтись без сортировки.
6.2.1. Детальный анализ производительности строчного хранилища
В этом пункте авторы представляют детальный анализ производительности строчного хранилища, используя в качестве ориентира планы выполнения запроса 2.1 из SSBM, сгенерированные System X (выбран именно этот запрос, потому что он один из немногих, для которых разделение по orderdate не обеспечивает выигрыша, и поэтому он предоставляет более равные возможности для сравнения традиционного подхода с подходом вертикального разделения). Хотя планы для других запросов не анализировались настолько же тщательно, их общая структура является такой же. Вот формулировка этого запроса на языке SQL:
SELECT sum(lo.revenue), d.year, p.brand1
FROM lineorder AS lo, dwdate AS d,
part AS p, supplier AS s
WHERE lo.orderdate = d.datekey
AND lo.partkey = p.partkey
AND lo.suppkey = s.suppkey
AND p.category = ‘MFGR#12’
AND s.region = ‘AMERICA’
GROUP BY d.year, p.brand1
ORDER BY d.year, p.brand1
Селективность этого запроса равняется 8.0×10-3. Здесь подход с вертикальным разделением работает почти так же хорошо, как и традиционный подход (65 секунд по сравнению с 43 секундами), но подход с использованием только индексов показывает существенно худшие результаты (360 секунд). Причины этого обсуждаются ниже.
Традиционный подход. При применении традиционного подхода этот запрос выполняется путем просмотра всей таблицы LINEORDER c использованием метода хэш-соединений для соединения этой таблицы с таблицами DATE, PART и SUPPLIER (в этом порядке). Затем производится вычисление агрегатной функции (на основе сортировки) для выдачи окончательного результата. Основные расходы по времени уходят на сканирование таблицы LINEORDER, что на системе авторов заняло около 40 секунд. Работа с материализованными представлениями заняла всего 15 секунд, поскольку при этом пришлось прочитать только около трети объема данных, требовавшегося при применении традиционного подхода.
Вертикальное разделение. При использовании подхода с вертикальным разделением столбец partkey соединяется (методом хэш-соединения) с отфильтрованной таблицей PART, столбец suppkey соединяется с отфильтрованной таблицей SUPPLIER, и затем оба результирующие множества хэш-соединяются. В результате получаются удовлетворяющие условию запроса кортежи с идентификаторами записей из таблицы фактов и атрибутом p.brand1 из таблицы PART. Затем System X соединяет их (методом хэш-соединения) с таблицей DATE для получения d.year и в завершение использует еще одно хэш-соединение для получения столбца lo.revenue из соответствующей колоночной таблицы. При применении этого подхода требуется полностью (последовательно) прочитать четыре столбца таблицы LINEORDER, для чего, как уже говорилось, приходится считать с диска почти столько же данных, что и при использовании традиционного подхода. И именно это сканирование доминирует при выполнении запроса, делая производительность сравнимой с производительностью традиционного подхода. Хэш-соединения в этом случае снижают производительность почти на 25%. Авторы пытались избавиться от хэш-соединений путем определения кластеризованных B-деревьев на ключевых столбцах каждого вертикального раздела, но System X все равно предпочла использовать хэш-сединения.
Планы с доступом только к индексам. В этих планах доступ ко всем столбцам производится через некластеризованные B-деревья, и столбцы одной и той же таблицы соединяются по идентификаторам записей (переход по указателям к хранимым отношениям никогда не производится). В плане для запроса 2.1 выполняется полное индексное сканирование столбцов suppkey, revenue, partkey и orderdate таблицы фактов, и затем результаты соединяются методом хэш-соединений. В этом случае индексное сканирование обеспечивает относительно быстрый просмотр всего индексного файла, и при этом не требуется подвод дисковых головок при переходе от одной листовой страницы к другой. Однако хэш-соединения выполняются довольно медленно, поскольку приходится комбинировать пары из 60 миллионов экземпляров столбцов, каждый из которых занимает сотни миллионов мегабайт дискового пространства. Заметим, что для этого случая хэш-соединение, по-видимому, является наилучшим методом, поскольку результаты индексного сканирования не упорядочены по идентификаторам записей, и выполнение сортировки списков идентификаторов записей или применение индексных вложенных циклов, вероятно, были бы гораздо медленнее. Как обсуждается ниже, авторам не удалось найти способ принудить System X отложить выполнение этих соединений на более позднюю фазу плана, что позволило бы приблизить эффективность этого подхода к эффективности подхода с вертикальным разделением.
После соединения столбцов таблицы фактов в плане используется индексное сканирование в диапазоне значений ключа для извлечения отфильтрованного столбца part.category, и результат хэш-соединяется со столбцами part.brand1 и part.part-key (доступ к которым производится путем полного индексного сканирования). Затем полученный результат хэш-соединяется с уже соединенными столбцами таблицы фактов. После этого выполняется хэш-соединение столбца supplier.region (отфильтрованного путем индексного сканирования в диапазоне значений ключа) со столбцом supplier.suppkey (доступ к которому производится путем полного индексного сканирования), и результат этого соединения хэш-соединяется с таблицей фактов. Наконец, используется полное индексное сканирование столбцов dwdate.datekey и dwdate.year, они хэш-соединяются, и результат этого соединения хэш-соединяется с таблицей фактов.
6.2.2. Обсуждение
Приведенные результаты показывают, что ни одна из попыток авторов эмулировать колоночное хранилище в строчном хранилище не привела к сколько-нибудь эффективным результатам. Подход вертикального разделения может обеспечить производительность, сравнимую с производительностью традиционного подхода (или немного более высокую) при выборке всего нескольких столбцов. Однако при выборке более чем четверти от общего числа столбцов непроизводительные затраты дискового пространства на хранение заголовков кортежей и избыточных копий идентификаторов кортежей приводят к производительности, худшей, чем у традиционного подхода. Для применения этого подхода также требуется выполнение дорогостоящих операций хэш-соединения для реконструкции кортежей таблицы фактов. Возможно, от System X можно было бы добиться хранения столбцов на диске в отсортированном порядке и использования для реконструирования кортежей соединения со слиянием (без сортировки), но соавтор-администратор баз данных не смог убедить систему вести себя таким образом.
Планы с доступом только к индексам обладают низкими покортежными накладными расходами, но порождают другую проблему – система вынуждена соединять столбцы таблицы фактов с использованием дорогостоящих операций хэш-соединения до того, как будет произведена фильтрация таблицы фактов на основе столбцов измерений. Как представляется авторам, System X не может отложить выполнение этих соединений на более позднюю фазу плана (как это делается в подходе вертикального разделения), потому что не может удержать идентификаторы записей из таблицы фактов после ее соединения с другой таблицей. Эти гигантские хэш-соединения приводят к исключительно низкой производительности.
Что касается традиционных планов, очевидным победителем является подход материализованных представлений, поскольку он позволяет System X считывать с диска именно то подмножество данных из таблицы фактов, которое требуется для выполнения запроса, без потребности в соединении столбцов. Иногда помогают битовые индексы – особенно при низкой селективности запросов, – поскольку они позволяют системе пропускать некоторые страницы таблицы фактов при ее сканировании. В ряде других случаев они приводят к снижению производительности, поскольку слияние битовых последовательностей добавляет накладные расходы к плану выполнения запроса, и сканирование через битовый индекс может быть медленнее чисто последовательного сканирования.
Наконец, авторы замечают, что реализация этих планов в System X была довольно тягостным делом. Для использования подхода вертикального разделения пришлось переписывать все запросы, авторы были вынуждены интенсивно использовать подсказки оптимизатору и другие хитрости, чтобы убедить систему делать то, что они хотели.
В следующем подразделе описывается, как в разработанной с нуля системе с хранением данных по столбцам удалось избежать этих ограничений и анализируется вклад разных механизмов в общую производительность системы C-Store при выполнении тестового набора SSBM.