Расширенная оптимизация подзапросов в Oracle
Срикант Белламконда, Рафи Ахмед, Анжела Амор, Мохамед Зэйд
Перевод Леонида Борчука
Под ред. Сергея Кузнецова
Оригинал: Enhanced Subquery Optimizations in Oracle / Srikanth Bellamkonda, Rafi Ahmed, Andrew Witkowski, Angela Amor, Mohamed Zait, Chun-Chieh Lin // Proceedings of the 35th international conference on Very large data base, 2009, pp. 1366 — 1377
6. Антисоединение с учетом наличия неопределенных значений
В этом разделе обсуждается вариант
антисоединения, появившийся в 11g и называемый антисоединением с учетом наличия неопределенных значений (null-aware antijoin, NAAJ). В большинстве приложений
достаточно часто используются подзапросы с <> ALL (т.е. NOT IN), так как
разработчики приложений находят синтаксис подзапросов с <> ALL более интуитивно-понятным, чем синтаксис примерно эквивалентных конструкций с NOT EXISTS. Вложенность подзапросов с NOT EXISTS
устраняется c использованием антисоединения. Семантика антисоединения прямо
противоположна семантике внутреннего соединения, поскольку строка из левой таблицы становится кандидатом в результат только в том случае, когда она не соединяется ни с одной из строк
правой таблицы. Мы называем эту операцию обычным антисоединением. Как правило, в коммерческих
СУБД обычное антисоединение может использоваться для устранения вложенности
подзапросов с <> ALL только в случаях, когда все столбцы в квантифицированном сравнении гарантированно не содержат неопределенных значений. Имеется другая стратегия, описанная в [9], в которой для учета возможности появления неопределенных значений используются дубликат таблицы и дополнительное антисоединение.
В SQL операция <> ALL может трактоваться как
конъюнкция неравенств. Аналогично можно трактовать операции < ALL, <= ALL, > ALL и >= ALL. В стандарте SQL поддерживается троичная логика и,
следовательно, любое реляционное сравнение с неопределенными значениями всегда вычисляется в UNKNOWN. Например, предикаты 7 = NULL, 7 <> NULL, NULL = NULL, NULL <> NULL вычисляются в UNKNOWN, и это логическое значение отличается от FALSE тем, что его отрицание тоже равняется UNKNOWN. Если
итоговым результатом раздела WHERE является FALSE или UNKNOWN, то соответствующая строка
отфильтровывается. Рассмотрим запрос Q23, содержащий подзапрос с >= ALL.
Q23
SELECT T1.C
FROM T1
WHERE T1.x <> ALL (SELECT T2.y
FROM T2
WHERE T2.z > 10);
Предположим, что подзапрос возвращает набор
значений {7,11,NULL}, а в T1.x имеется следующий набор значений: {NULL,5,11}.
Операция >= ALL может быть выражена как T1.x <> 7 AND T1.x <> 11 AND
T1.x <> NULL. Это выражение вычисляется в UNKNOWN, так как
T1.x <> NULL всегда вычисляется в
UNKNOWN независимо от значения T1.x. Поэтому для этого набора значений
Q23 вообще не вернет строк. Обычное антисоединение, если его использовать в этом
случае, некорректно вернет {NULL,5}.
6.1. Алгоритм антисоединения с учетом наличия неопределенных значений
Как показывает запрос Q24, в Q23 может быть устранена
вложенность подзапроса с использованием NAAJ. Для представления NAAJ
используется следующая нестандартная нотация: T1.x NA= T2.y, где T1 и T2 —
левая и правая таблицы антисоединения с учетом наличия неопределенных значений соответственно.
Q24 SELECT T1.C FROM T1, T2 WHERE T1.x NA= T2.y AND T2.z > 10;
Поясним семантику NAAJ на примере Q24. NAAJ
выполняется после вычисления всех предикатов
фильтрации над правой таблицей. Поэтому, когда мы
говорим о T2 в последующем объяснении, имеется в виду набор данных, полученный
путем применения предиката T2.z > 10
к исходной таблице T2.
- Если T2 не содержит строк, то вернуть все строки T1 и завершить работу.
- Если любая строка T2 содержит неопределенные значения во всех столбцах, участвующих в условии NAAJ, то не возвращать никаких строк и завершить работу.
- Если строка T1 содержит неопределенные значения во всех столбцах, участвующих в условии NAAJ, то не возвращать эту строку.
- Для каждой строки T1, если
условие NAAJ вычисляется в
TRUEилиUNKNOWNдля какой-либо строки T2, то не возвращать эту строку T1; иначе вернуть эту строку T1.
Шаг 1 аналогичен соответствующему шагу обычного антиcоединения; т.е. если правая часть пуста, то возвращаются все строки левой части, включая те из них, которые содержат неопределенные значения в условии антисоединения. Отметим, что шаги 2 и 3
поглощаются шагом 4, но их явное наличие позволяет выполнить антисоединение более
эффективно, если все столбцы соединения левой или правой строки содержат неопределенные значения. Шаг 4 существенно отличает NAAJ от обычного
антисоединения. Тогда как в обычном
антисоединении, если условие
антисоединения вычисляется в UNKNOWN, то строка левой таблицы возвращается, в NAAJ она не возвращается. Далее будут
представлены стратегии выполнения NAAJ. Для антисоединений с участием
нескольких столбцов эти стратегии являются сложными, и мы проиллюстрируем их с использованием запроса Q25.
Q25
SELECT c1, c2, c3
FROM L
WHERE (c1, c2, c3) <> ALL (SELECT c1, c2, c3
FROM R);
6.2. Стратегии выполнения NAAJ
В соответствии с семантикой NAAJ строка левой части может соединяться
с несколькими строками правой части (соответствовать нескольким строкам). Например, строка левой
части, которая содержит неопределенное значение в одном из соединяемых столбцов, будет
соответствовать строкам правой части, которые содержат любое значение в соответствующем столбце. В этом случае условие NAAJ вычисляется в UNKNOWN, и,
следовательно, строка не возвращается. Пусть, например, левая
таблица L из запроса Q25 содержит строку (null, 3, null). Предположим, что правая таблица R содержит две строки: R = {(1,
3, 1), (2, 3, 2)}. Хотя в R отсутствует строка (null, 3, null), нашей строке из L соответствуют
обе строки R, поскольку столбец c2 в обеих строках содержит значение 3. Поэтому строка (null, 3, null) не возвращается.
Методы выполнения обычного антисоединения посредством сортировки со слиянием или хеширования расширяются: по мере построения требуемой структуры данных теперь они собирают информацию о том, какие столбцы соединения содержат неопределенные значения.
После этого выполняются шаги 1 и 2, описанные в подразделе 6.1, для раннего завершения выполнения соединения, возвращающего все строки или не возвращающего ни одной строки. В случае, когда эти шаги не срабатывают, для каждой строки левой части мы ищем соответствующую строку в правой части (если на шаге 3 алгоритма, приведенного в подразделе 6.1, эта строка не исключается). Если на любом из следующих трех шагов, описываемых ниже, соответствие обнаруживается, то строка левой части отбрасывается, как и в обычном антисоединении.
- Поиск в отсортированной структуре данных или хеш-таблице для правой части на предмет наличия точного соответствия.
-
Поиск других возможных соответствий с использованием собранной информации о неопределенных значениях. Например,
предположим, что имеются три столбца соединения c1, c2 и с3, но в правой части неопределенные значения имеются только в столбцах c1 и c2. Если поступающая на обработку строка левой части содержит значения
(1,2,3), то в структуре доступа к правой части ищутся строки(1,null,3),(null, 2, 3)и(null, null, 3). -
Если в одном или нескольких столбцах соединения строки левой части
содержится неопределенное значение, то создается
дополнительная структура доступа для столбцов, не содержащих неопределенные значения (если она еще не строилась). Например, предположим, что строка левой части
содержит значения
(null, 2, 3). Для правой части создается дополнительная отсортированная структура данных или хеш-таблица с использованием столбцов c2 и с3, и далее в новой структуре данных ищутся строки(x, 2, 3),(x, 2, null),(x, null, 3)и(x, null,null).
Если
вести учет всех возможных схем расположения неопределенных значений в правой части, становится возможна дальнейшая оптимизация.
Используя пример, приведенный выше при описании шага 3, предположим, что нам известен факт наличия в
правой части строки, содержащой неопределенное значение null в столбцах c2 и с3.
Эта строка будет соответствовать любой строке левой части, у которой c1 содержит неопределенное значение. В этом случае строка левой части (null, 2, 3) может
быть немедленно исключена, и не требуется построение дополнительной структуры доступа. Эта информация также может быть использована для исключения некоторых поисковых действий, выполняемых на шаге 2.
Оптимизация ключа из одного столбца: Если в условии NAAJ участвует только один столбец (как, например, в запросе Q24), то стратегия выполнения существенно упрощается. Строки левой части, содержащие неопределенное значение в столбце соединения, могут быть пропущены или включены в результат без реального поиска соответствий в зависимости от того, имеются или не имеются в правой части какие-либо строки.
7. Исследование производительности
Эксперименты по производительности проводились на схеме 30G TPC-H. Использовалась машина под управлением OC Linux с 8 двухъядерными процессорами (400 MHz) и 32 GB оперативной памяти. Машина была соединена с общим хранилищем данных под управлением Oracle Automated Storage Manager. Пропускная способность системы ввода-вывода общего хранилища данных была несколько ограничена по сравнению с мощностью процессоров, и это показано в экспериментах по распараллеливанию. Для параллельного выполнения всех запросов использовались все процессоры (если при описании эксперимента явно не оговорено иное).
7.1. Сращивание подзапросов
Рассмотрим наш запрос Q4, являющийся упрощенной версией
запроса 21 из TPC-H. По сравнению с Q4 исходный запрос 21 из TPC-H содержит две
дополнительные таблицы orders и nation и предикаты селекции, ограничивающие
данные заданной страной (nation). В схеме представлены 25 стран, данные
которых распределены равномерно. Сращивание подзапросов, описанное в подразделе 2.2, преобразует Q4
в Q5. На рис. 5 показано
время выполнения преобразованного (Q5) и непреобразованного (Q4) вариантов запроса как функция от количества стран. В среднем повышение производительности составило 27%.
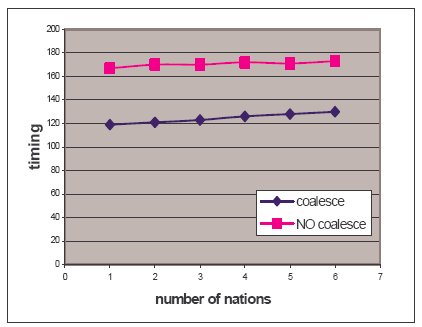
Рис.5. TPC-H Q21, сращивание подзапросов
7.2. Исключение представлений с группировкой
В этом эксперименте использовался запрос Q8,
представляющий собой упрощенный вариант запроса 18 из TPC-H. Метод исключения
представлений с группировкой, описанный в подразделе 3.1, позволяет исключить представление с
группировкой, устраняя излишние ссылки на
таблицу lineitem, что в результате приводит к запросу Q11. Значение константы в предикате раздела HAVING изменялось в
пределах от 30 до 300, так что подзапрос возвращал от 2000 до
34000000 строк (это показано на оси X).
На рис. 6 представлены результаты эксперимента.
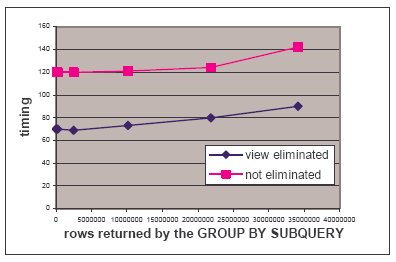
Рис.6. TPC-H Q18, исключение представления
Преобразование к Q11 может представлять проблему для оптимизатора, поскольку предикат раздела HAVING задан на агрегате, и оптимизатору сложно оценить мощность отфильтрованного множества. Если эта оценка будет заниженной, то оптимизатор может выбрать для выполнения соединения метод вложенных циклов, а не
метод хеширования, что приведет к снижению производительности.
7.3. Удаление подзапросов с использованием оконных функций
Для иллюстрации этого вида оптимизации выполнялись запросы 2, 11, 15 и 17 из тестового набора TPC-H. На рис. 7 представлено время выполнения оптимизированных (qN.opt) и неоптимизированных запросов. Преобразованные запросы Q15 и Q16 (аналоги запросов 2 и 17 из TPC-H) продемонстрировали резкое повышение производительности. Для запроса 2 из TPC-H время выполнения сократилось в 24 раза за счет того, что путем оконного преобразования было устранено нескольких операций сканирования и соединения таблиц.
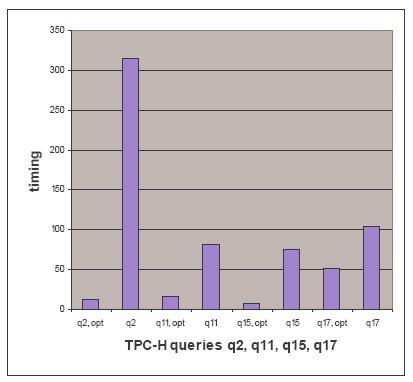
Рис.7. Удаление подзапросов с использованием оконных функций
На рис. 8 иллюстрируется эффект от удаления некореллированного
подзапроса путем оконного преобразования в запросе 15 из TPC-H как функция от числа месяцев, сканируемых в таблице lineitem. Оптимизационный переход от Q17 (исходный запрос) к Q18
(преобразованный запрос) разъясняется в подразделе 4.2. Как показывает рис. 8, в результате этого преобразования время выполнения сократилось в 8,4 раза.
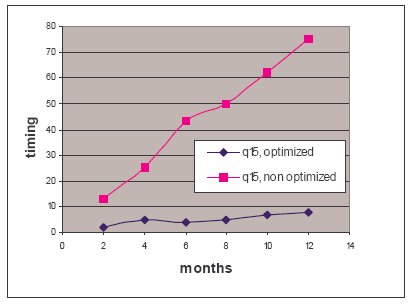
Рис.8. TPC-H Q15, удаление некореллированного подзапроса
Заметим, что удаление подзапросов с использованием оконных функций оказывает очень эффективное воздействие на время выполнения запросов TPC-H. В среднем производительность запросов q2, q11, q15 и q17 повысилась в 10 раз.
7.4. Масштабируемое выполнение оконных функций
Для иллюстрации эффекта от распараллеливания оконных функций без раздела PBY использовался
следующий запрос к таблице lineitem:
SELECT SUM(l_extprice) OVER () W FROM lineitem;
Запрос выполнялся с применением и без применения усовершествованных методов распараллеливания, описанных в разд. 5, и степень параллелизма (degree of parallelism, DOP) изменялась от 2 до 16. На рис. 9 представлены результаты этого эксперимента.
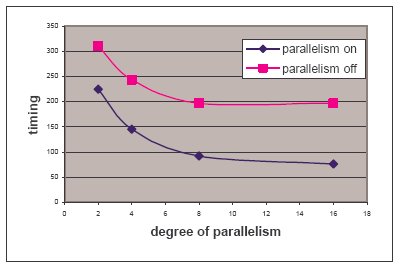
Рис.9. Распараллеливание оконной функции без PBY
Заметим, что даже если оконная функция не распараллеливается, сканирование таблицы по-прежнему выполняется параллельно. Сканирующие подчиненные процессы посылают свои данные координатору запроса, который затем вычисляет оконную функцию. Вследствие этого, при степени параллелизма, равной 2, производительность преобразованного запроса возрастает немного меньше, чем в 2 раза. Рис. 9 также показывает, что при DOP > 8 система не масштабируется линейно при дальнейшем росте DOP из-за ограниченной пропускной способности нашей совместно используемой дисковой системы.
7.5. Антисоединение с учетом наличия неопределенных значений
Для демонстрации повышения производительности за счет использования антисоединения с учетом наличия неопределенных значений проводилось две группы экспериментов.
В экспериментах первой группы использовался запрос Q26, выдающий из заданного списка
поставщиков имена поставщиков, у которых не было заказов в заданном месяце (в январе 1996 г.). В
этой схеме L_SUPPKEY может содержать неопределенные значения, а S_SUPPKEY — нет.
Q26
SELECT s_name FROM supplier
WHERE s_suppkey in (<supplier_list>) AND
s_suppkey <> ALL
(SELECT l_suppkey FROM lineitem
WHERE l_shipdate >>= '1996-01-01' AND
l_shipdate < '1996-02-01');
Без использования NAAJ вложенность подзапроса в Q26 устранить невозможно, а это приводит к
коррелированному выполнению, когда мы
должны выполнять подзапрос для каждой строки таблицы поставщиков. Такой запрос выполняется мучительно долго, поскольку для вычисления коррелированного предиката невозможно использовать индексное зондирование (index probe). Это связано с тем, что Oracle преобразует подзапрос с ALL в
подзапрос с NOT EXISTS и использует коррелированный предикат, который эквивалентен предикату
(l_suppkey IS NULL OR l_suppkey = r_suppkey).
Единственным достоинством выполнения этого запроса без использования NAAJ
является разделение таблицы
lineitem по l_shipdate, позволяющее сократить объем сканирования до одного раздела.
Рис. 10 иллюстрирует
прирост производительности при возрастании числа поставщиков до 40. Преобразованный запрос выполняется с использованием антисоединения таблиц
supplier и lineitem с учетом наличия неопределенных значений; антисоединие вычисляется на основе хэширования.
Второй эксперимент проводился на реальной рабочей нагрузке — 241000 запросов, производимых Oracle Applications. Схема содержит около 14 000 таблиц, представляющих приложения кадровой службы (human resources), финансовые приложения (financial), приложения приема заявок (order entry), CRM, управления цепочкой поставок (supply chain) и т.д. Базы данных большинства приложений имеют сильно нормализованные схемы. Число таблиц в запросах варьируется между 1 и 159, в среднем — 8 таблиц на запрос.
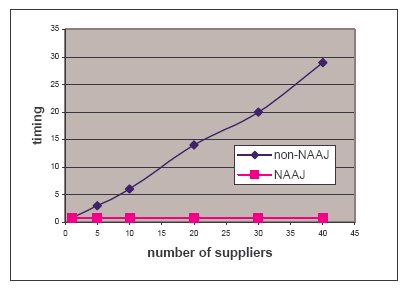
Рис.10. Выполнение запроса без NAAJ и с NAAJ
Имелось 72 запроса с DISTINCT и подзапросами с <> ALL, пригодных для выполнения на основе NAAJ. Для 68 из них при использовании
NAAJ затраченное процессорное время сократилось в среднем в 736730 раз! Один запрос выполнялся 350 секунд без
использования NAAJ и 0,001 секунды — с использованием NAAJ. Время выполнения 4 запросов увеличилось в среднем в 100 раз, причем в наихудшем случае затраченное процессорное время увеличилось c 0,000001 секунды до
0,016 секунды.
8. Родственные работы
Методы устранения вложенности подзапросов различного типа активно изучались ранее [1], [2], [3], [4], [9]. В нашей системе поддерживаются почти все эти разновидности методов устранения вложенности с примененем как эвристических, так и основанных на оценке стоимости стратегий. В ранней работе, посвященной преобразованиям запросов [2], предлагается метод вытягивания агрегатов и группировки в позицию дерева операций, предшествующую соединению. Похожий алгоритм применялся в ранних версиях Oracle (8.1 и 9i). Преобразование инициировалось эвристиками на фазе преобразования запроса. В Oracle 11g для размещения операций группировки и удаления дубликатов, а также их коммутирования с соединениями [5] [6] используется инфраструктура, основанная на оценке стоимости [8]. Некоторые методы удаления подзапросов с использованием оконных функций опубликованы в [13]. Неформальные ссылки, содержащиеся в [12], наводят на мысль, что метод устранения подзапросов с группировкой обсуждался где-то еще. Мы показываем, каким образом подобный метод может быть включен в оптимизатор Oracle. Работы, посвященные сращиванию подзапросов, антисоединению с учетом наличия неопределенных значений и масштабируемому вычислению оконных функций, в опубликованной литературе не обсуждались.
9. Заключение
Подзапросы – это мощный компонент языка SQL, повышающий его уровень декларативности и выразительных возможностей. В статье кратко описываются расширенные возможности оптимизации подзапросов в реляционной СУБД Oracle. Эти преобразования выполняются на основе инфрастуктуры преобразований Oracle, основанной на оценке стоимости. Важным вкладом3 статьи является описание ряда новых методов преобразования запросов — методов сращивания подзапросов (subquery coalescing), удаления подзапросов с использованием оконных функций (subquery removal using window functions), исключения представлений в запросах с группировкой (view elimination for group-by queries), антисоединения с учетом наличия неопределенных значений (null-aware antijoin), а также методов параллельного выполнения. Исследование производительности показывает, что эти оптимизации обеспечивают значительное сокращение времени выполнения сложных запросов.10. Благодарности
Авторы хотели бы выразить признательность Тьерри Круанесу (Thierry Cruanes) за инфрастуктуру взаимодействий процесса QC с подчиненными процессами, Натану Фолкеру (Nathan Folkert) и Санкару Субраминьяну (Sankar Subramanian) за распараллеливание некоторого класса оконных функций с использованием этой инфраструктуры. Сьюзи Фэн (Susy Fan) заслуживает огромной благодарности за ее помощь при проведении экспериментов по оценке производительности.
11. Список литературы
[1] W. Kim, «On Optimizing an SQL-Like Nested Query», ACM TODS, September 1982.
[2] U. Dayal, «Of Nests and Trees: A Unified Approach to Processing Queries that Contain Nested Subqueries, Aggregates, and Quantifiers», Proceedings of the 13th VLDB Conference, Brighton, U.K., 1987.
[3] M. Muralikrishna, «Improved Unnesting Algorithms for Join Aggregate SQL Queries», Proceedings of the 18th VLDB Conference, Vancouver, Canada, 1992.
[4] H. Pirahesh, J.M. Hellerstein, and W. Hasan, «Extensible Rule Based Query Rewrite Optimizations in Starburst», Proc. of ACM SIGMOD, San Diego, USA, 1992.
[5] S. Chaudhuri and K. Shim, «Including Group-By in Query Optimization», Proceedings of the 20th VLDB Conference, Santiago, Chile, 1994.
[6] W.P.Yan and A.P.Larson, «Eager Aggregation and Lazy Aggregation», Proceedings of the 21th VLDB Conference, Zurich, Switzerland, 1995.
[7] A. Witkowski, et al, «Spreadsheets in RDBMS for OLAP», Proc. of ACM SIGMOD, San Diego, USA, 2003.
[8] R. Ahmed, et al, «Cost-Based Query Transformation in Oracle», Proceedings of the 32th VLDB Conference, Seoul, S. Korea, 2006.
[9] M. Elhemali, C. Galindo-Legaria, et al, «Execution Strategies for SQL Subqueries», Proc. of ACM SIGMOD, Beijing, China, 2007.
[10] A. Eisenberg, K. Kulkarni, et al, «SQL: 2003 Has Been Published», SIGMOD Record, March 2004.
[11] F. Zemke, «Rank, Moving and reporting functions for OLAP», 99/01/22 proposal for ANSI-NCITS.
[12] C. Zuzarte, et al, «Method for Aggregation Subquery Join Elimination», http://www.freepatentsonline.com/7454416.html
[13] C. Zuzarte, H. Pirahesh, et al, «WinMagic: Subquery Elimination Using Window Aggregation», Proc. of ACM SIGMOD, San Diego, USA, 2003.
[14] TPC Benchmark H (Decision Support), Standart Specification Rev 2.8, http://tpc.org/tpch/spec/tpch2.8.0.pdf
[15] TPC-DS Specification Draft , Rev 32, http://tpc.org/tpcds/spec/tpcds32.pdf
3Для части работ, описанных в этой статье, рассматривается вопрос о выдаче патентов США.