Система моделирования Grid: реализация и возможности применения
Грушин Д.А., Поспелов А.И.
Институт системного программирования РАН (ИСП РАН), Москва
3. Эксперименты
Цель экспериментов заключалась в следующем. С использованием реализованного прототипа среды смоделировать поведение реально существующей Grid системы при различных условиях. В качестве распределенной Grid системы была выбрана сеть Sharcnet [18].
Распределенная вычислительная система Sharcnet (Shared Hierarchical Academic Research Computing Network) – это консорциум из 16 колледжей и университетов в юго-западной части провинции Канады Онтарио, вычислительные ресурсы которых объединены высокоскоростной оптической сетью (рисунок 5).
Рисунок 5: Схема распределенной вычислительной системы Sharcnet
Характеристики вычислительных ресурсов сети Sharcnet представлены в таблице 2.
| Имя | Процессоры | Узлы |
|---|---|---|
| Bruce | 128 | 32 x 4 x Opteron |
| narwhal | 1068 | 267 x 4 x Opteron dual core |
| Tiger | 128 | 32 x 4 x Opteron |
| Bull | 384 | 96 x 4 x Opteron |
| megaladon | 128 | 32 x 4 x Opteron |
| Dolphin | 128 | 32 x 4 x Opteron |
| Requin | 1536 | 768 x 2 x Opteron |
| Whale | 3072 | 768 x 4 x Opteron |
| Zebra | 128 | 32 x 4 x Opteron |
| Bala | 128 | 32 x 4 x Opteron |
Таблица 2: Характеристики вычислительных ресурсов сети Sharcnet
В качестве входных данных была использована запись реального потока задач (“workload“ поток), выполнявшихся на кластерах с декабря 2005 по январь 2007 года [15]. Характеристики потока представлены на рисунке 6.
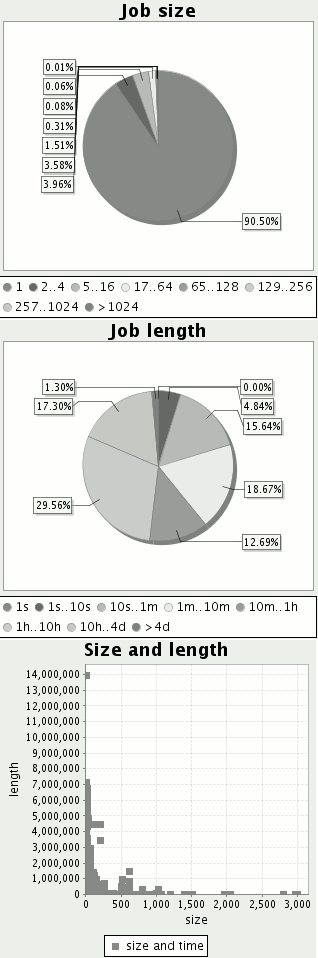
Рисунок 6: Характеристики потока задач в сети Sharcnet: распределение ширины задач (количество запрашиваемых процессоров), длины задач, соотношение ширины и длины. Время показано в секундах
Данный поток состоит по большей части из однопроцессорных задач. Однако, параллельных задач достаточно много – примерно 10%. Длина задач распределена более равномерно – большая часть, примерно 30%, имеет длину от 1 до 10 часов и чуть более половины всех задач по длительности составляют меньше одного часа, включая все большие параллельные задачи.
На рисунке 7 представлен график суммарного числа запрашиваемых процессоров в единицу времени. По оси абсцисс отложено время в секундах, по оси ординат – суммарное число запрашиваемых процессоров. Синяя горизонтальная линия показывает общее число процессоров в системе.
Рисунок 7: Суммарное число запрашиваемых процессоров в единицу времени
Мы видим, что поток не равномерный, на протяжении всего интервала присутствуют всплески запрашиваемого количества процессоров. Также, на графике можно заметить периодичность изменения нагрузки – временные интервалы 5000000, 1000000, 15000000 и т.д. Данные особенности присущи практически всем реальным потокам [3]. Примерно в середине временного интервала происходит перегрузка системы – запрашиваемая ширина становится больше доступной. Это говорит о том, что при любом распределении задач, в системе будут присутствовать очереди. Для данного потока, с 10% параллельных задач, будет происходить неполное заполнение кластеров, что еще больше увеличит размер очередей.
Особенность данного потока состоит также в том, что пользователи направляли задачи на кластеры непосредственно – для распределения не использовался брокер. При анализе потока оказалось, что в системе присутствует существенный дисбаланс нагрузки (рисунок 8).
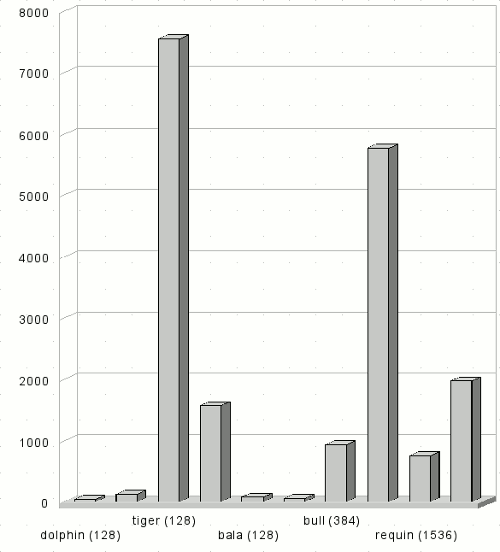
Средняя длина очереди на каждом кластере
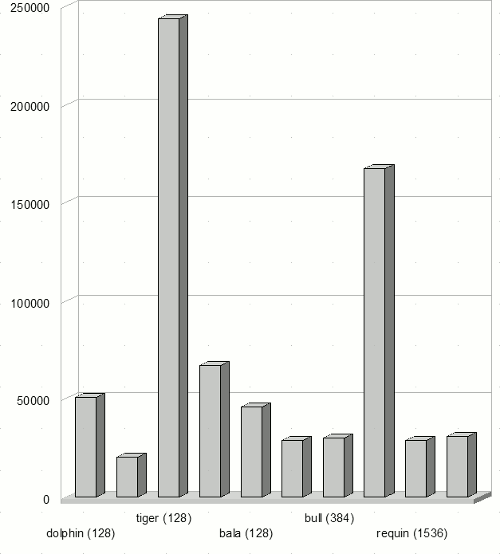
Среднее время ожидания на каждом кластере
Рисунок 8: Дисбаланс в системе Sharcnet
Средние длины очередей в некоторых случаях отличаются почти в 100 раз. Это приводит к тому, что среднее время ожидания в очереди для различных кластеров отличается в несколько десятков раз.
Для проведения экспериментов, на основе данного потока мы создали несколько синтетических потоков. Необходимость использования синтетических потоков обусловлена различными факторами:
- запись оригинального потока может содержать различные несистематические особенности и всплески, связанные с конкретными событиями, что делает его неподходящим для анализа и прогнозирования поведения данной системы, но эти особенности могут быть сглажены при создании синтетических потоков;
- оригинальные потоки часто имеют большой размер и поэтому не очень удобны для выявления локальных свойств алгоритмов;
- синтетические потоки могут позволить создавать новые ситуации, которых не было в исходных данных.
Для создания синтетических потоков могут быть использованы различные подходы. Полностью синтетические потоки иногда бывают удобны для отладки, однако для анализа поведения моделируемых систем более подходящим является использование синтетических потоков, основывающихся на записях оригинальных потоков [5].
Для создания таких синтетических потоков мы использовали следующий поход. Для того чтобы определить поток задач
![]()
необходимо определить следующие параметры:
- Rj — промежуток времени между поступлением j и j+1 задачи
(j = 1,2,…,M-1); - Hj — запрашиваемое время исполнения
(j = 1,2,…,M); - Wj — запрашиваемое число процессоров
(j = 1,2,…,M).
На основе оригинального потока задач для этих параметров оцениваются кумулятивные функции распределения и первые моменты. Далее, для каждого из параметров подбирается функция распределения в виде свертки нескольких распространенных функций распределения. Подбор осуществляется с помощью минимизации отклонения моментов и графиков функций по параметрам распределений в свертке и коэффициентам свертки.
Полученные таким образом распределения были использованы для генерирования нескольких синтетических потоков.
Мы применили разработанную систему моделирования и сравнили эффективность распределения задач в сети Sharcnet в оригинальном случае (без брокера) с распределением, получаемым с помощью брокера. Без брокера задачи поступали на кластеры в оригинальной последовательности, указанной в файле загрузки. В обоих случаях на каждом кластере использовалась реализация алгоритма Backfill.
Алгоритм обратного заполнения Backfill работает по следующему принципу: размещая наиболее приоритетное задание, определяется момент времени, когда освободится достаточное количество ресурсов, занятых уже выполняющимися заданиями, затем производится резервирование этих ресурсов. Задание с меньшим приоритетом может быть запущено вне очереди, но только в том случае, если оно не будет мешать запуску более приоритетных заданий [6].
На брокере использовались различные алгоритмы распределения. В каждом случае вначале брокер выбирает множество кластеров, которые могут выполнить данную задачу – W≥Wj, где W – число узлов кластера, а Wj – число узлов, запрашиваемых задачей, а затем выбирает один кластер исходя из заданного критерия:
- N/W Выбирается кластер с наименьшим числом задач в очереди. Для данного кластера отношение N/W имеет минимальное значение, где N – число задач, стоящих в очереди, W – число процессоров кластера.
- W/W Выбирается кластер с минимальной общей шириной задач в очереди. Для данного кластера отношение
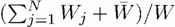 имеет минимальное значение, где N – число задач, стоящих в очереди, Wj – ширина задачи, W – ширина отправляемой задачи, W – число процессоров кластера.
имеет минимальное значение, где N – число задач, стоящих в очереди, Wj – ширина задачи, W – ширина отправляемой задачи, W – число процессоров кластера.
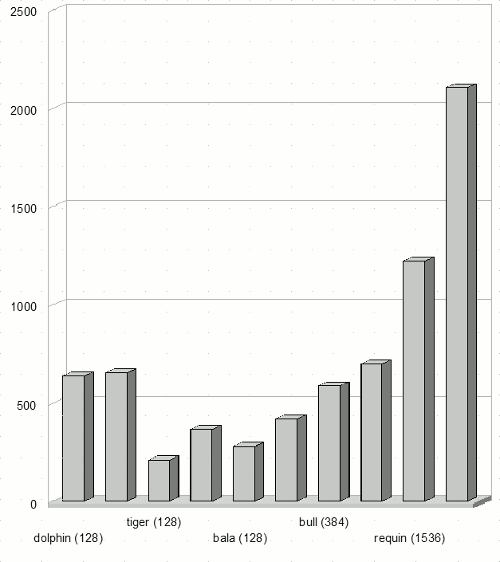
- Sqr/W Выбирается кластер с минимальной общей площадью задач в очереди. Для данного кластера отношение
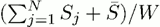 имеет минимальное значение, где N – число задач, стоящих в очереди, Sj – площадь задачи, S – площадь отправляемой задачи, W – число процессоров кластера.
имеет минимальное значение, где N – число задач, стоящих в очереди, Sj – площадь задачи, S – площадь отправляемой задачи, W – число процессоров кластера.
Всего было проведено 7 экспериментов:
- задачи распределялись на кластеры согласно файлу загрузки;
- задачи направлялись на брокер, который затем распределял их на кластеры. На брокере использовалась эвристика N/W;
- на брокере использовалась эвристика W/W;
- на брокере использовалась эвристика Sqr/W;
- на брокер направлялись только однопроцессорные задачи. Параллельные задачи направлялись на кластеры согласно файлу загрузки. На брокере использовалась эвристика N/W;
- однопроцессорные задачи, на брокере использовалась эвристика W/W;
- однопроцессорные задачи, на брокере использовалась эвристика Sqr/W
Мы сравнивали среднее время ожидания задач в очереди, а также характеристики самих очередей – длину и площадь, среднюю по всем кластерам и отдельно для каждого кластера.
(a) Среднее время ожидания в очереди
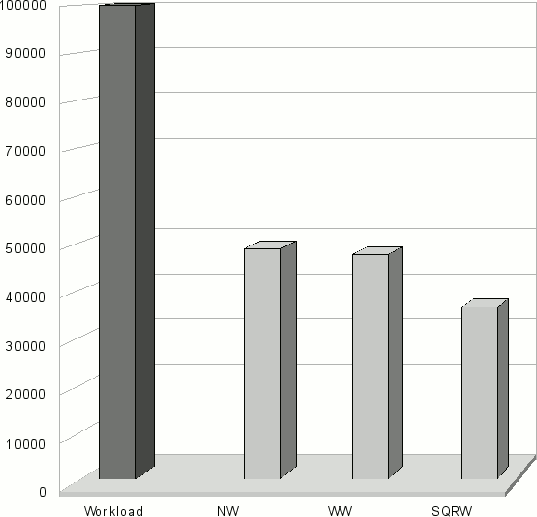
(b) Средняя длина очереди
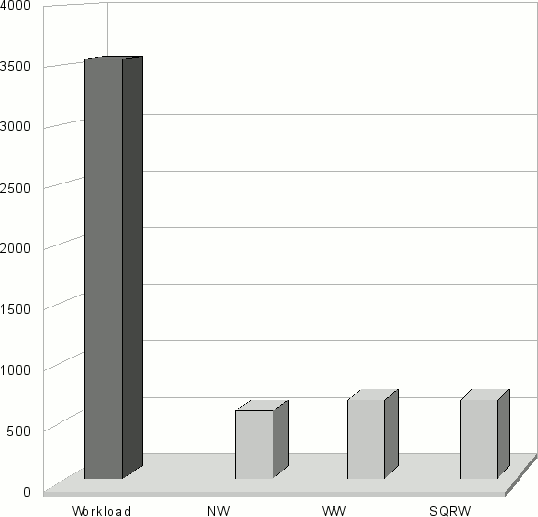
(c) Средняя длина очереди на каждом кластере. Распределение однопроцессорных задач, алгоритм Sqr/W
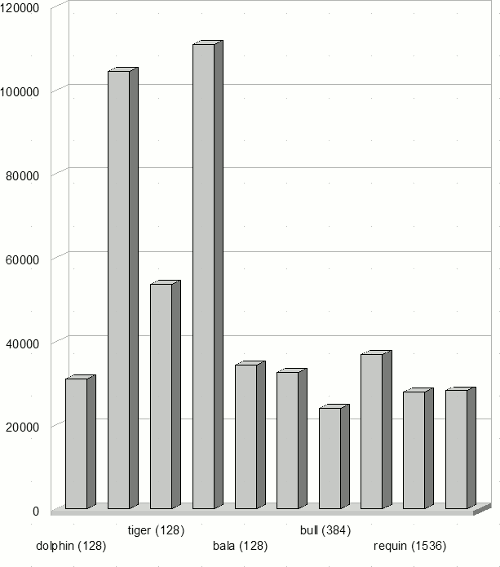
(d) Среднее время ожидания на каждом кластере. Распределение однопроцессорных задач, алгоритм Sqr/W
Рисунок 9: Результаты экспериментов
На рисунке 9 представлены результаты экспериментов при распределении только однопроцессорных задач. На рисунке 9(a) показано среднее время ожидания в очереди, определяемое как
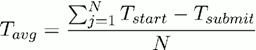
где N – общее число запущенных задач, Tstart – время запуска задачи, Tsubmit – время постановки задачи в очередь кластера. На рисунке 9(b) показана средняя длина очереди. Первый столбец на обеих диаграммах соответствует распределению задач без брокера. На рисунках 9(c) и 9(d) показаны средняя длина очереди и среднее время ожидания на каждом кластере в секундах.
Результаты показывают, что для данной вычислительной системы распределение потока однопроцессорных заданий через брокер дает значительный эффект: снижается среднее время ожидания заданий в очереди, а также происходит более равномерная загрузка вычислительных ресурсов.
При распределении всех задач (не только однопроцессорных) через брокер среднее время ожидания становится примерно на 5-7% меньше, чем в приведенных результатах. Однако, мы приводим результаты для распределения только однопроцессорных задач, поскольку для проведения данных экспериментов нам была доступна информация только в виде записи потока задач. Из записи потока невозможно определить, почему задача отправляется пользователем на тот или иной вычислительный ресурс. Причиной может быть архитектура системы, наличие специального программного обеспечения, личные пристрастия и т.п. Мы сделали предположение, что однопроцессорные задачи менее привязаны к конкретному кластеру, так как не зависят от среды передачи данных, которая установлена на кластере. Для системы Sharcnet такое предположение наиболее логично, так как среда передачи данных не одинакова для всех кластеров – таблица 3.
| Имя | Процессоры | Архитектура |
|---|---|---|
| Bruce | 128 | Myrinet 2g (gm) |
| Narwhal | 1068 | Myrinet 2g (gm) |
| Tiger | 128 | Myrinet 2g (gm) |
| Bull | 384 | Quadrics Elan4 |
| megaladon | 128 | Myrinet 2g (gm) |
| Dolphin | 128 | Myrinet 2g (gm) |
| Requin | 1536 | Quadrics Elan4 |
| Whale | 3072 | Gigabit Ethernet |
| Zebra | 128 | Myrinet 2g (gm) |
| Bala | 128 | Myrinet 2g (gm) |
Таблица 3: Среда передачи данных кластеров сети Sharcnet
Похожие результаты были получены в работе голландских исследователей при объединении двух Grid систем – Grid5000 и DAS2 [9]. В их работе отмечается наличие дисбаланса в обеих системах, и предлагается метод для его устранения, используя глобальный планировщик. Результаты также показывают существенное уменьшение времени ожидания, примерно на 60%, и более равномерную загруженность кластеров.
В ходе проведенных нами экспериментов было замечено, что результаты распределения сильно зависят от входного потока задач. Очень трудно найти алгоритм распределения, который давал бы одинаково хорошие результаты на всех возможных потоках. Однако, зная характеристики вычислительной системы и характеристики предполагаемого потока задач, мы можем провести моделирование и определить, какой алгоритм распределения показывает наиболее хороший результат. В некоторых случаях простая эвристика может давать лучшие результаты по сравнению с более сложной.
В связи с этим актуальной представляется задача разработки такого алгоритма управления вычислительными ресурсами, при котором брокер анализирует поступающий к нему поток задач и, в зависимости от характеристик потока, выбирает эвристику, дающую оптимальное, согласно заданным критериям, распределение. Выбранная эвристика используется брокером для распределения задач по кластерам до тех пор, пока не произойдет ”переключение“ на другую эвристику.
4. Заключение
В статье представлена среда моделирования, разработанная в ИСП РАН, позволяющая оценивать поведение распределенных вычислительных систем при изменяющихся условиях и, на основе этого, оптимизировать стратегии управления потоками задач. Также представлены результаты использования реализованного прототипа данной среды на моделировании реально существующей вычислительной системы Sharcnet.
В будущем нам хотелось бы развивать данную систему как инструмент для оценки эффективности управления вычислительными ресурсами в Grid. Пользователями такой системы могут быть администраторы и исследователи, разрабатывающие новые алгоритмы управления ресурсами.
В ближайшее время предполагается провести эксперименты с задачами, требующими передачи больших объемов данных. Также мы планируем расширить функциональность генератора синтетических потоков.
Система является свободно распространяемым с открытым исходным кодом программным пакетом и доступна по адресу http://gridme.googlecode.com.
Литература
- Buyya R., Murshed M. Gridsim: a toolkit for the modeling and simulation of distributed resource management and scheduling for grid computing // Сoncurrency and computation: practice and experience. — 2002. — Vol. 14. — Pp. 1175–1220.
- Eclipse - an open development platform www.eclipse.org.
- Feitelson D. G. Locality of sampling and diversity in parallel system workloads // ICS ’07: Proceedings of the 21st annual international conference on Supercomputing. — ACM, 2007. — Pp. 53–63.
- Feitelson D. G., Rudolph L. Metrics and benchmarking for parallel job scheduling // Lecture Notes in Computer Science. — 1998. — Vol. 1459. — Pp. 1+.
- Feitelson D. G. Workload modeling for computer systems performance evaluation book draft. — since 2005.
- Feitelson D. G., Weil A. M. Utilization and predictability in scheduling the IBM SP2 with backfilling // 12th Intl. Parallel Processing Symp. — 1998. — Pp. 542–546.
- Globus alliance. — www.globus.org.
- The grid workloads archive. — http://gwa.ewi.tudelft.nl/pmwiki/.
- Inter-operating grids through delegated matchmaking / A. Iosup, D. H. Epema, T. Tannenbaum et al. // Proceedings of International Conference for High Performance Computing, Networking, Storage and Analysis (SC07). — Reno, NV: 2007. — November.
- Legrand A., Marchal L., Casanova H. Scheduling distributed applications: The simgrid simulation framework // Proceedings of the 3rd IEEE/ACM International Symposium on Cluster Computing and the Grid 2003 (CCGrid2003). — 2003. — Pp. 138–145.
- The microgrid: Using emulation to predict application performance in diverse grid network environments / H. Xia, H. Dail, H. Casanova, A. Chien // In Proceedings of the Workshop on Challenges of Large Applications in Distributed Environments (CLADE’04). IEEE Press. — 2004.
- Tuecke S., Czajkowski K., Foster I. et al. Open grid services infrastructure (ogsi) version 1.0. — 2003. — June.
- Optorsim - a grid simulator for studying dynamic data replication strategies / W. Bell, D. Cameron, L. Capozza et al. // International Journal of High Performance Computing Applications. — 2003. — Vol. 17, no. 4. — Pp. 403–416.
- Overview of a performance evaluation system for global computing scheduling algorithms / A. Takefusa, S. Matsuoka, K. Aida et al. // Proceedings of the Eighth IEEE International Symposium on High Performance Distributed Computing (HPDC’99). — 1999. — Pp. 97–104.
- Parallel workloads archive. — http://www.cs.huji.ac.il/labs/parallel/workload/.
- Foster I., Kesselman C., Nick J., Tuecke S. The physiology of the grid an open grid services architecture for distributed systems integration. — 2003.
- Platform globus toolkit. — http://www.platform.com/.
- The shared hierarchical academic research computing network. — www.sharcnet.ca.
- Univa. — http://www.univa.com.