Визуальные средства поиска информации в документоориентированных базах данных
В. Плешко, Гарант-Парк
Постоянно растущий поток документов, проходящих через информационное пространство предприятий, все чаще заставляет менеджеров информационных систем искать новые решения по автоматизации документооборота. Основная проблема, которая встает перед пользователем, имеющим дело с большими массивами документов - это быстрое получение необходимой информации. Современные системы автоматизации документооборота предлагают в основном следующие четыре вида поиска:
- поиск по атрибутам,
- гипертекстовые ссылки,
- тематические рубрикаторы,
- контекстный поиск.
Редко случается, когда документы приходят в нескольких заранее установленных и неизменных форматах, и появляется возможность создать средства поиска документов по атрибутам. В общем случае автоматически удается отслеживать лишь минимальный набор атрибутов, как-то: время поступления документа, источник.
Системы автоматизированной сортировки документов пока еще редко встречаются и довольно дороги. Автору не известно ни одной такой системы, работающей с русским языком. Самый простой выход из такой ситуации - это нанять экспертов по конкретной тематике для сортировки документов по рубрикам. Однако, как показывает опыт, с ростом потока документов, качество работы экспертов по заполнению рубрикатора снижается.
Расстановка гипертекстовых ссылок опять-таки лежит целиком на плечах экспертов. Этот процесс поддается автоматизации только в простейших случаях, например, обнаружении в тексте адресов Internet или терминов из толкового словаря.
Контекстный поиск - это единственный полностью автоматизируемый вид поиска. Он хорошо работает в качестве дополнения к предыдущим средствам. Но на больших объемах информации, когда нет возможности поддерживать рубрикатор или выделить атрибуты документов, и контекстный поиск является единственным инструментом, получение пользователем нужной информации сопряжено со значительными трудностями. Тот, кто хотя бы раз пользовался услугами поисковых серверов в Internet, например, http://www.altavista.com, тот наверняка сталкивался с тем, что ответ на запрос может состоять из нескольких тысяч документов.
Поэтому уже сейчас необходимы дополнительные средства, не требующие специальных форматов представления документов, полностью автоматизированные и позволяющие сузить контекст поиска.
Другая сторона разработки систем поиска информации - это улучшение пользовательского интерфейса. В идеале интерфейс должен быть предельно простым, и пользователь должен иметь возможность получать информацию посредством одного щелчка мыши.
Естественно, что любая новая технология, позволяющая хотя бы частично решить вышеперечисленные проблемы, представляет большой интерес для любого, кому приходится сталкиваться с большими объемами информации.
С начала своего существования фирма "Гарант-Парк" ( http://www.park.ru) активно занимается исследованиями по развитию методов поиска и упорядочения информации для полнотекстовых баз данных. Эти исследования напрямую связаны с деятельностью компании по разработке и поддержке WWW-версии СПС "Гарант", которая хорошо известна широкому кругу пользователей, а также молодой, но быстро развивающейся информационной системы "Парк", ориентированной на предоставление информации экономического характера. Специалисты "Гарант-Парка" постоянно следят за новинками в области новых информационных технологий и пополняют банк данных фирмы информацией о перспективных направлениях. Так, в январе этого года из нескольких кандидатов на внедрение была выбрана новая и перспективная технология, которая, по нашему мнению, может претендовать на роль дополнительного средства поиска в документоориентированных базах данных. Речь идет о методе WebSOM, предназначенном для публикации документоориентированных баз данных в виде карты плотностей на плоскости.
WebSOM является аббревиатурой слов Web Self-Organization Maps, что можно перевести, как самоорганизующиеся карты (SOM) для Web. Данная технология была разработана группой ученых, возглавляемой профессором Хельсинкского Технологического Университета Т. Кохоненом. Первая публикация на эту тему в Internet была в январе 1996 года по адресу http://websom.huf.fi/websom/. Там доступны статьи с описанием метода и демонстрацией визуального представления массивов документов из групп новостей Internet.
Специалистам "Гарант-Парка" пришлось адаптировать данную технологию к русскому языку, и совсем недавно демонстрационная версия русского WebSOM появилась на сервере "Гарант- Парка" по адресу http://www.park.ru/websom/.
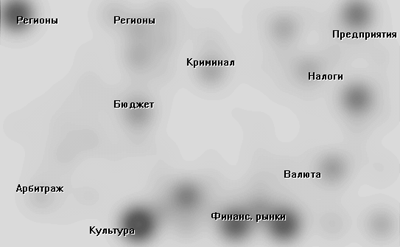
Рис.1. Пример применения метода WebSOM для 1300 документов, случайно отобранных из ИС "Парк". Документы связаны с узлами на карте. Чем ближе содержание документов, тем ближе отвечающие им узлы. Доступ к документам осуществляется щелчком мыши
Визуально (рис. 1) предметная область представлена, как карта с разнородной окраской, где
более темные области соответствуют большему числу документов. В зависимости от содержания
документов области карты поименованы. Пользователь с помощью мышки выбирает любую
точку на карте и получает соответствующие ей документы. Для получения документов,
содержание которых находится на пересечении нескольких категорий (именно так в
терминологии WebSOM называются разделы предметной области), достаточно кликнуть
мышкой в точку, расположенную между или на пересечении областей этих категорий. В общем и
целом, придумать что-либо проще, с точки зрения пользовательского интерфейса, трудно.
В методе WebSOM можно выделить два основных этапа - подготовка категорий смысловых
единиц (фактически - это разделы предметной области, которую предстоит описывать карте) и
построение карты документов (это та картинка, с которой в результате будет работать
пользователь). При подготовке категорий смысловых единиц исходят из того, что смысловая
единица - это объект, однозначно идентифицируемый в тексте, и отвечающий какому-либо
понятию. Например, слово, слово с дополнительной информацией, словосочетание. Категория
смысловых единиц - множество смысловых единиц, отвечающих одному и тому же понятию.
Грубо говоря, в категорию "криминал" попадают смысловые единицы "преступление",
"убийство", "ограбление"... Эти категории необходимы для построения смысловых портретов
документов. Смысловой портрет документа - это многомерный вектор, отражающий содержание
документа. Категории смысловых единиц можно готовить как заранее для заданной предметной
области, так и автоматически. Здесь, собственно говоря, и основное различие оригинального и
адаптированного методов WebSOM. В оригинальном WebSOM это делалось автоматически, с
использованием семантических самоорганизующихся карт (SSOM). В адаптированном, в силу
особенностей русского языка, от этого пришлось отказаться - категории смысловых единиц
создаются вручную, а затем могут использоваться для построения карт по конкретной
тематике.
При автоматическом построении каждый документ сначала подвергается лексическому анализу,
при котором удаляются служебные символы и части речи. Затем документ подается на вход
семантической самоорганизующейся карты для обучения. Семантическая самоорганизующаяся
карта представляет собой специально обученную SOM и служит для выделения слов, близких по
смыслу в категории. Основная идея здесь состоит в предположении, что слова, близкие по
смыслу, употребляются в сходном контексте, т.е. у близких по смыслу слов распределение слов,
употребляемых до и после должны быть близки. В результате получается карта категорий слов,
представляющая собой двухмерный массив, с каждым элементом которого связан список слов.
Предполагается, что слова, связанные с соседними элементами отвечают близким по смыслу
понятиям (рис. 2).
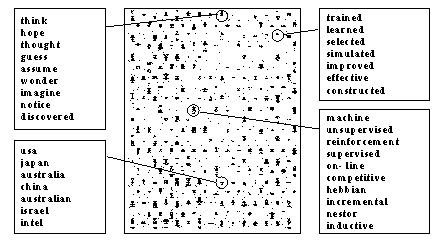
Рис. 2 Пример семантической самоорганизующейся карты, построенной при экспериментах группы Кохонена с группой новостей comp.ai.nueral-nets. В узлах карты очень мелким шрифтом написаны, слова попавшие в узлы. В выносках приведено содержимое ряда удачных узлов.
Все это оказалось хорошо для английского языка, но как часто бывает, сломалось на русском.
Менее строгая модель построения предложений, большее влияние стиля документа и тот факт,
что большинство понятий русского языка составляют словосочетания (согласно исследованиям
профессора Г.Г. Белоногова - более 60%), привели к тому, что оригинальная модель не пошла.
Попытки специалистов из "Гарант-Парка" заставить ее удовлетворительно работать с русским
языком успехом не увенчались. В результате в адаптированном WebSOM пришлось подойти к
вопросу организации категорий по другому. Смысловой единицей в нем считается
словосочетание, а выделением категорий смысловых единиц вручную занимаются эксперты.
Второй этап - построение карты документов в обоих вариантах метода реализован одинаково.
После лексического анализа подсчитывается, сколько раз в документе встретилась каждая из
категорий (т.е. сколько раз встретились смысловые единицы, входящие в категорию). В
результате получается гистограмма категорий, представляющая собой смысловой портрет
документа. Смысловые портреты документов подаются на вход карты категорий слов -
происходит обучение карты. После обучения карта раскрашивается пропорционально
плотности распределения смысловых портретов (чем больше документов в области, тем она
темнее) и, затем, размечается экспертом в зависимости от содержания областей.
Таким образом, при существующей карте категорий слов можно создавать карты, содержащие
сколь угодно много документов, причем система сама будет располагать документы на карте в
зависимости от содержания - задача администратора будет состоять только в переразметке
карты и введении, по-необходимости, новых категорий.
Фирма "Гарант-Парк" собирается активно продвигать эту технологию. Ко всему
вышесказанному можно добавить, что WebSOM от "Гарант-Парка" - это на данный момент
единственная коммерческая реализация данной технологии. И вообще, похоже, единственная
реализация данного метода, кроме реализации его авторов из Хельсинкского Технологического
Университета. Во всяком случае, поиск в Internet больше не дал ни одного адреса. Так что можно
с гордостью заявить, что в данном случае российская фирма оказалось первопроходцем, что в
последнее время случается крайне редко.
Перспективы же у WebSOM, при работающей реализации, достаточно радужные. Во-первых,
она будет добавлена в качестве визуального метода поиска в информационную систему "Парк"
( http://www.park.ru). Естественно там же она будет
использоваться для автоматической сортировки документов, в дополнение к уже готовому
рубрикатору ИС "Парк". В систему можно ввести такой сервис, как "ловушки" для документов -
можно отслеживать документы, попадающие в некоторую, представляющую особый интерес
область карты. Естественно сам алгоритм предполагает достаточно простую реализацию поиска
документов, похожих на данный по содержанию. WebSOM представляет собой готовый полигон
для социологических исследований. С его помощью можно отслеживать пики плотности
распределения, строить карты для документов, датированных определенными отрезками времени
и по пикам плотности и взаимному расположению областей отслеживать эволюцию тематики и
акцентов для новостийных лент, входящей информации, телеконференций. С другой стороны
предполагается развитие WebSOM в сторону трехмерного представления информации из
предметной области. Так что, вполне возможно, скоро начнутся разработки реализации
WebSOM на VRML, специальном языке моделирования трехмерных миров в WWW.