Программная среда для динамического анализа бинарного кода
В.А. Падарян, А.И. Гетьман, М.А. Соловьев
Труды Института системного программирования РАН
3. Среда TrEx
Общая схема устройства среды TrEx представлена на рис. 1. Пользователь взаимодействует со средой через графический интерфейс, предоставляя на входе трассу и получая на выходе ассемблерный листинг интересующего его алгоритма. Модули, принципиально обязанные учитывать специфику процессорной архитектуры, на которой выполняется программа, выделены жирным шрифтом. Эти компоненты позволяют располагать внутренним представлением, предоставляющим достаточное количество информации для работы средств анализа. При этом большинство из них не требуют специфических знаний об архитектуре. Даже если такие требования и возникают, например, в случае построителя листинга, происходит декомпозиция на базовый класс и набор производных классов, реализующих вспомогательные методы, где и расположено знание о семантике инструкций и выводных форматах ассемблера.
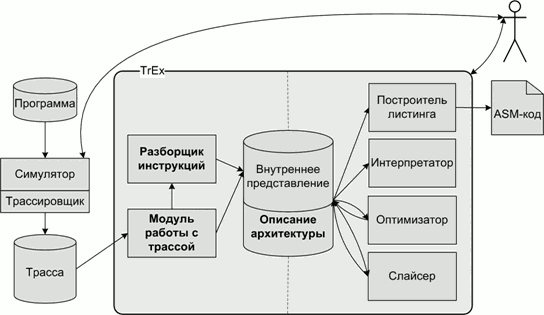
Рис. 1. Общая схема работы среды TrEx.
Далее будут рассмотрены некоторые особенности среды, такие как: аритектурнонезависимое API для работы средств анализа, возможности свертки вызовов функций, пользовательский интерфейс на основе скриптового языка.
3.1. Модель процессора общего назначения
Одним из поставленных требований было не закладывать в основы среды привязки к какой-либо процессорной архитектуре. Добиться выполнения этого требования удалось благодаря разработке Common API – библиотеки, предоставляющий архитектурнонезависимый интерфейс к трассировочным данным. В нем можно выделить три раздела, обеспечивающих доступ к описанию ресурсов вычислительной платформы, данным, сохраненным в трассе, и результатам разбора машинных инструкций.
Для описания регистрового файла, портов ввода-вывода и оперативной памяти машины в единообразном виде вводится модель адресных пространств. С точки зрения вводимой модели описываемая процессорная архитектура представляет собой набор адресных пространств, каждое из которых имеет свою разрядность адреса (рассматриваются разрядности в 8, 16, 32 и 64 бита). Элементами этих адресных пространств называются последовательные блоки, описываемые начальным адресом (с битовой частью) и длиной (также с битовой частью). Над элементами определены операции:
- ElementsIntersect. Проверка, имеют ли два указанных элемента пересечение как соответствующие области своих адресных пространств. При этом предполагается, что элементы различных адресных пространств пересечений не имеют.
- CompareElements. Сравнение элементов: для пары элементов e1; e2 указывается отношение между ними "<", ">" или "=". Конкретных требований к способу сравнения не предъявляется, однако данная операция обязана задавать полное отношение порядка на множестве элементов.
Обе операции можно задать, ограничившись лишь знанием об адресах и размерах рассматриваемых элементов. Однако в общем случае из соображений производительности может потребоваться для некоторых часто используемых элементов (таких, как, например, регистры) использовать статически заданные или однократно заполняемые таблицы.
С этой позиции оказывается удобным немного усложнить модель, введя понятие именованных элементов. Для каждого адресного пространства определяется множество (возможно, пустое) имен, с каждым из которых сопоставляется некоторый элемент этого адресного пространства. Элементы, имеющие имена, и будем называть именованными. Стоит отметить, что, несмотря на принципиальную возможность использования в рамках одного адресного пространства элементов с именами и без них, на практике такой необходимости не возникает. Причина заключается в том, что потребность в присвоении имен обнаружилась только в отношении регистров, а для них на рассмотренных процессорных архитектурах не подразумевается произвольный доступ к части регистра.
Для поддержки именованных элементов необходимо ввести операции их перечисления (EnumerateNamedElements) и получения описания элемента по его имени (GetNamedElementDescription).
Предложенная модель позволяет единообразно описывать вершины графа зависимостей по данным, порождаемого выполнением инструкций трассы. В то же время сохраняется информация о виде элемента данных (регистр, порт ввода-вывода, память), которая может быть полезна при проведении анализа с более детальным учетом семантики инструкций трассы. Помимо того, предложенный подход позволяет описывать «вложенные» регистры, присутствующие в архитектуре INTEL IA-32.
Модель является максимально простой. В частности, она в явном виде не предусматривает наличие нескольких наборов регистров (регистровые окна в SPARC или теневые наборы регистров в некоторых реализациях архитектуры MIPS) или нескольких параллельно существующих пространств виртуальной памяти. Однако поддержку подобных особенностей можно сделать на уровне декомпозиции инструкций на зависимости по данным. Так, для поддержки теневых наборов регистров достаточно указать в адресном пространстве регистров регистры из всех таких наборов, а при разборе инструкции отображать регистры в смысле MIPS на регистры модели из конкретного теневого набора.
Описав архитектуру целевой машины в терминах адресных пространств, мы получаем возможность единообразно задавать всевозможные элементы данных, с которыми работает эта машина. Как было указано выше, применительно к системе TREX трасса состоит из шагов, для каждого из которых указана выполнявшаяся инструкция и значения некоторого подмножества регистров машины. Вместо того, чтобы предлагать единый формат трассы для всех архитектур, можно ограничиться парой операций, определенных над шагом трассы (их реализация уже будет зависеть от целевого процессора и выбранного формата хранения трассы):
- GetInstruction. Сообщает, какая инструкция выполнялась на указанном шаге. Инструкция записана в бинарном виде (строка байтов) и требует декодирования. Кроме того, для процессорных архитектур с переменной дли-ной инструкции в силу особенностей проведения трассировки фактическая длина инструкции может также быть неизвестной до проведения декодирования. В последнем случае длина полагается равной максимально возможной для данного процессора (например, 15 для INTEL 64).
- GetItem. По указанному элементу модели адресных пространств целевой архитектуры сообщает его значение на данном шаге трассы перед выполнением соответствующей инструкции. Значение может оказаться неизвестным (например, значение запрошенного регистра вообще не трассировалось), в этом случае возвращается специальный признак «значение не-известно».
Легко видеть, что предлагаемый способ представления шагов трассы как интерфейс взаимодействия удовлетворяет требованиям:
- адекватности и полноты – указанный способ представления шагов трассы позволяет получать всю необходимую для работы системы информацию;
- минимальности – операции независимы и не выражаются друг через друга;
- простоты – нельзя представить предложенные операции в виде более мелких.
В качестве исходных данных для разбора инструкции выступают:
- Сама эта инструкция в бинарном виде. Может быть получена из шага трассы (операция GetInstruction, описанная выше) или из отпечатка памяти.
- Интерфейс для запроса значений регистров на момент выполнения инструкции. В случае работы с трассой этот интерфейс является прямым отображением на метод GetItem шага трассы, а в случае работы с памятью значения регистров полагаются неизвестными.
- Информация о режиме работы процессора. Так как некоторые процессорные архитектуры (например, INTEL IA-32) способны функционировать в нескольких режимах, поведение инструкций в которых отличается (за счет различных механизмов отображения памяти, разрядности операндов и т. д.), необходимо явно указывать, в каком режиме работы выполнялась инструкция. Разметка шагов трассы по режимам сохраняется параллельно с трассой на этапе ее сбора.
- Флаги декомпозиции на зависимости. На практике возникает необходимость исключать из рассмотрения при проведении слайсинга определенные категории зависимостей. Всего определено четыре таких категории.
4.1 ADDRESS. Зависимости по вычисленному адресу. Например, в инструкции INTEL IA-32 MOV EAX, [ECX+ESI*2-1] при включенном отслеживании адресных зависимостей необходимо во множество рассматриваемых элементов добавить регистры ECX, ESI и DS (сегментный регистр данных).
4.2 STACK. Зависимости по вычисленным адресам в стеке. При выключении этого флага адресные зависимости, соответствующие локальным переменным в стеке (в случае INTEL IA-32 это те адреса, в которых фигурирует регистр SP/ESP) не будут генерироваться.
4.3 FLAG. Зависимости по флагам. Если эта опция выключена, флаги процессора при декомпозиции на зависимости не учитываются.
4.4 CF. Зависимости по управлению. Этот флаг определяет, следует ли учитывать при декомпозиции регистр или регистры, являющиеся счетчиком инструкций (для INTEL IA-32 это CS и IP/EIP).
Флаги указываются аналитиком при проведении слайсинга. В совокупности указанные данные представляют собой задание на разбор, которое передается в компонент разборщика. Результатом являются блок информации об инструкции, в котором содержится в общем виде информация об инструкции и ее операндах; производится поверхностная классификация инструкций по признаку отношения к передаче управления и операндов по их типу:
- Мнемоника инструкции.
- Число операндов и информация о каждом из них в отдельности, включающая следующие пункты.
2.1 Классификация операнда в наиболее общем виде: константа; регистр или прямо указанный элемент памяти; элемент памяти, адресуемый косвенно.
2.2 Для операндов-констант предоставляется возможность запроса их значения.
2.3 Для операндов-регистров и ячеек памяти предоставляется возможность запроса соответствующих элементов в смысле модели адресных пространств. В случае косвенной адресации потребуется вычисление адреса, для чего используется переданная в задании ссылка на интерфейс запроса значений регистров.
- Классификация инструкции по признаку отношения к передаче управления. Инструкции делятся на классы: инструкции вызова, инструкции возврата, инструкции безусловной передачи управления, инструкции условной передачи управления, остальные инструкции. Следует отметить, что знания мнемоники инструкции часто оказывается недостаточно для того, чтобы отнести ее к определенному классу. Так, например, инструкция безусловного перехода по адресу, записанному в регистре, JR в архитектуре MIPS должна быть отнесена в общем виде к инструкциям безусловной передачи управления. В то же время, ее форма JR $31, согласно принятым соглашениям, используется только для возврата из подпрограмм, так что в итоге принадлежность к определенному классу зависит от операнда инструкции.
- Проверка, образуют ли две указанные инструкции пару «вызов-возврат».
Помимо того, требуется предоставлять информацию о зависимостях по данным, необходимую для работы алгоритма слайсинга. Декомпозиция инструкций производится на наборы троек <t, I, O>, где t - тип зависимости, I - множество входных элементов адресных пространств, а O - множество выходных элементов адресных пространств, фигурирующих в данной зависимости.
Выделены следующие 5 типов зависимостей:
- CHECK. Зависимость по управлению внутри инструкции (которая с точки зрения слайсинга все равно является зависимостью по данным).
- GET. Зависимость по косвенному адресу (чтение из памяти). В качестве примера можно привести зависимость от регистров DS, ESI в инструкции LODSB.
- KILL. Не являясь зависимостью как таковой, позволяет указать алгоритму слайсинга на тот факт, что во время выполнения инструкции некоторый элемент был уничтожен (т. е. его значение после выполнения инструкции непредсказуемо). Подобные ситуации характерны для флагов процессора INTEL IA-32.
- SET. Зависимость по косвенному адресу (запись в память), например зависимость от ES, EDI в инструкции STOSB.
- UPDATE. Все остальные зависимости по данным, не обладающие специальными свойствами.
Для описания предлагаемым образом некоторых инструкций (например, инструкции обмена XCHG процессора INTEL IA-32) необходимо использовать дополнительные теневые регистры, для которых определяется специальное адресное пространство, автоматически добавляемое ко всем моделям адресных пространств конкретных процессорных архитектур. Данное адресное пространство включает в себя 8 теневых регистров (S0-S7), каждый из которых может использоваться как 128-, 64-, 32-, 16- или 8-битный. Кроме того, определен один теневой битовый регистр SU.
После введения таких регистров инструкция XCHG распадается на три тройки:
{<U, {o0}, {S7}>, <U, {o1}, {o0}>, <U; {S7}, {o1}>}, где o{0, 1} – операнды инструкции.
Можно видеть, что такая запись удовлетворяет требованиям к исходным данным алгоритма слайсинга (т. к. является одной из возможных форм записи графа зависимостей по данным). Преимуществом перед графовым представлением является то, что можно работать с отдельными такими тройками, указывая, таким образом, какая именно из содержащихся в инст-рукции зависимостей по данным повлекла включение инструкции в слайс.
В рамках описанного способа представления целевой процессорной архитектуры, для поддержки архитектур INTEL IA-32 и MIPS64 были реализованы интерфейсы, соответствующие модели адресных пространств, подсистеме работы с трассой и разбору инструкций.